Retrieval Augmented Generation (RAG) for a YouTube playlist
Here is a step by step process to use Retrieval Augmented Generation (RAG) for a YouTube playlist.
Note: this requires the use of paid tools
Transcribe the YouTube video using TurboScribe
You can use TurboScribe to transcribe your YouTube videos.
Quite often, YouTube tutorial videos are part of a playlist or a course.
For example, the Intro to NLP with spaCy is a playlist.
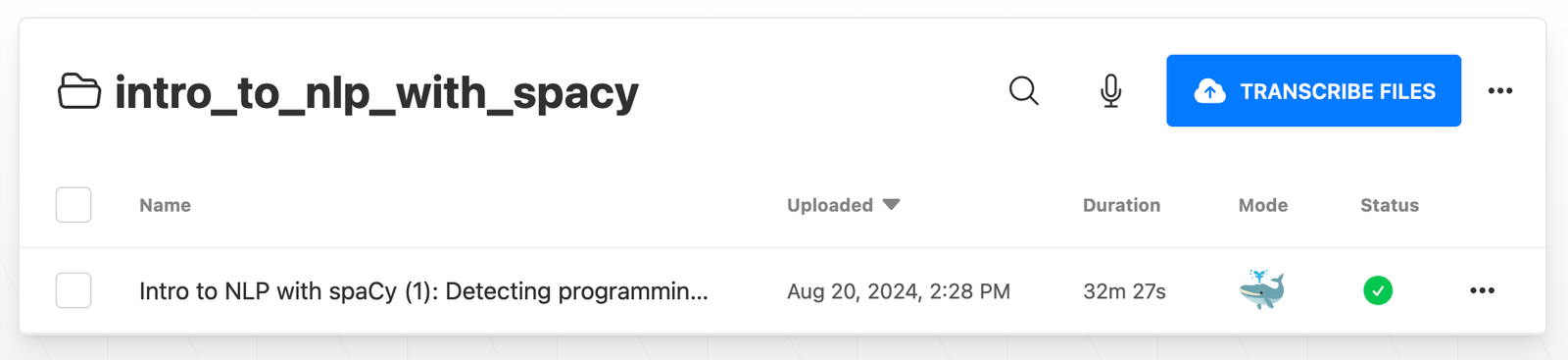
Once you create an account in TurboScribe, create a new folder to save the transcripts of all videos within a playlist.

Click on the Transcribe Files button.
In the modal dialog, click on the Link icon on the top right.
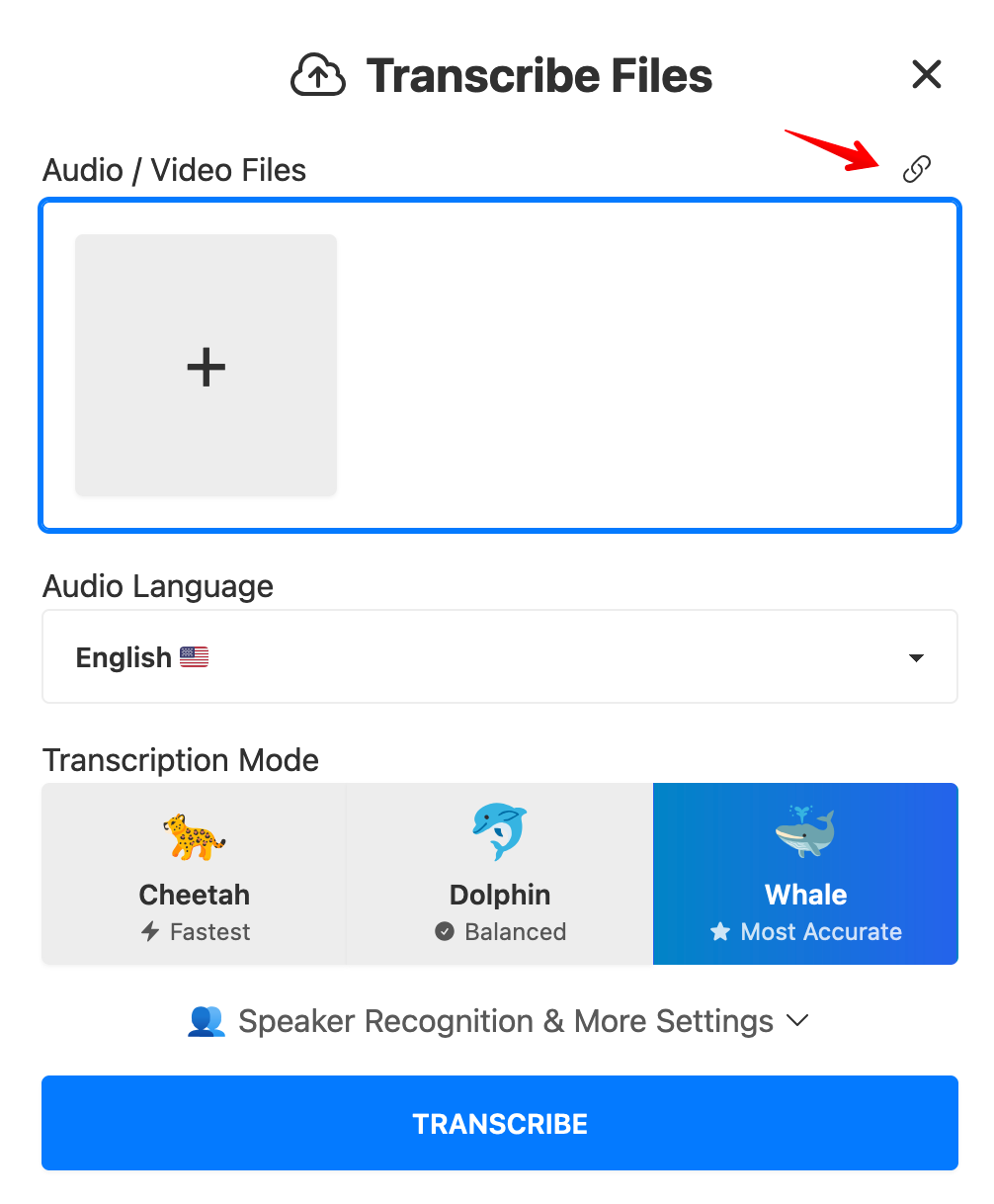
Choose appropriate transcription speed and other settings. I prefer highest quality transcripts even if it takes a little longer.
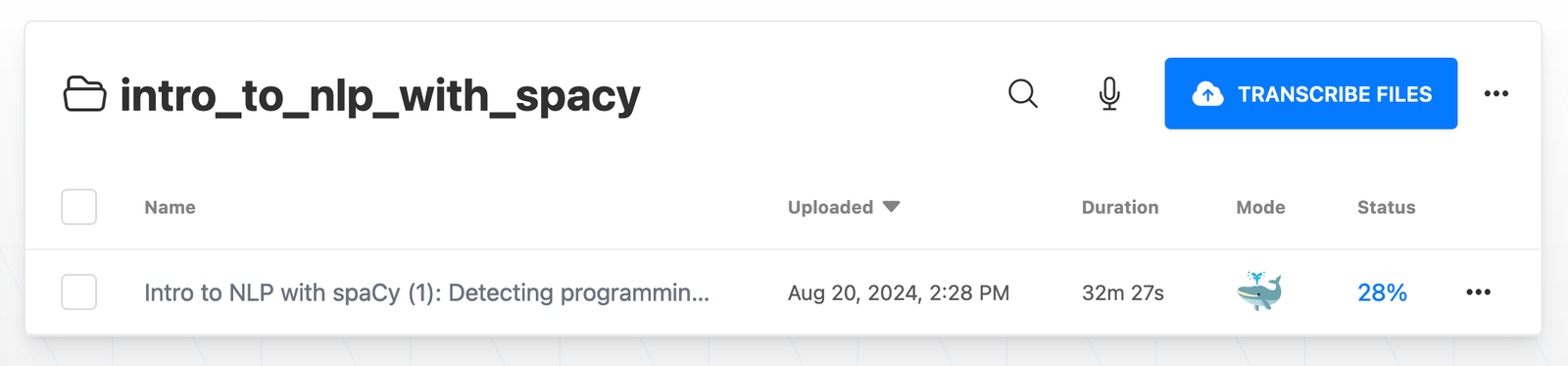
Notice that the status will indicate a percentage completion.
And the status will turn into a green check mark when the transcription is complete. The transcription speed is usually much quicker for paid accounts compared to the free accounts.
Prompt Google AI Studio and get a summary with timestamps
One of the most interesting things about Large Language Models (LLMs) like ChatGPT is their ability to summarize information.
I recommend Google AI Studio because
a) it is free for our purposes
b) it is pretty high quality
Log in to Google AI Studio using your Google account.
Click on Create New Prompt.

Add this in the System Instructions:
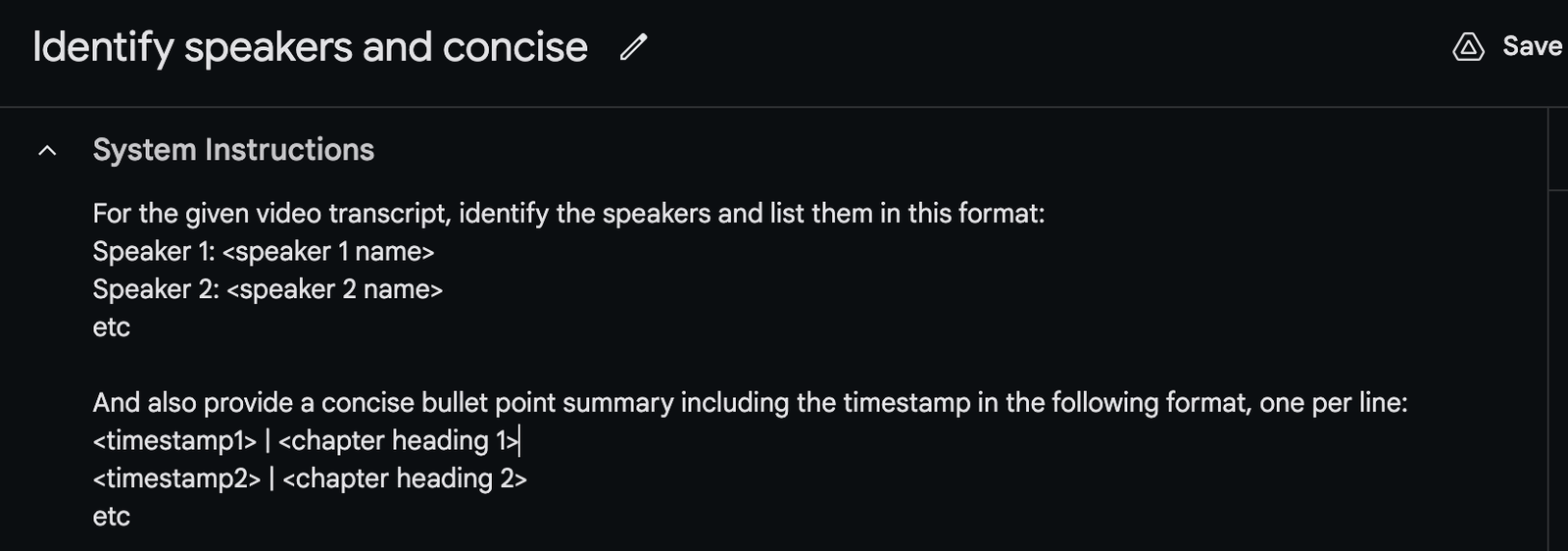
Copy/paste this text:
For the given video transcript, identify the speakers and list them in this format:
Speaker 1: <speaker 1 name>
Speaker 2: <speaker 2 name>
etc
And also provide a concise bullet point summary including the timestamp in the following format, one per line:
<timestamp1> | <chapter heading 1>
<timestamp2> | <chapter heading 2>
etc
Click on the transcript name inside TurboScribe to open the transcript.
Place the cursor anywhere within the transcript, and select all the text (usually CTRL + A)
This selects everything (including things we don’t need for this step)

Paste the whole text into a User Prompt. Select “Gemini 1.5 Pro Experimental” as your model.
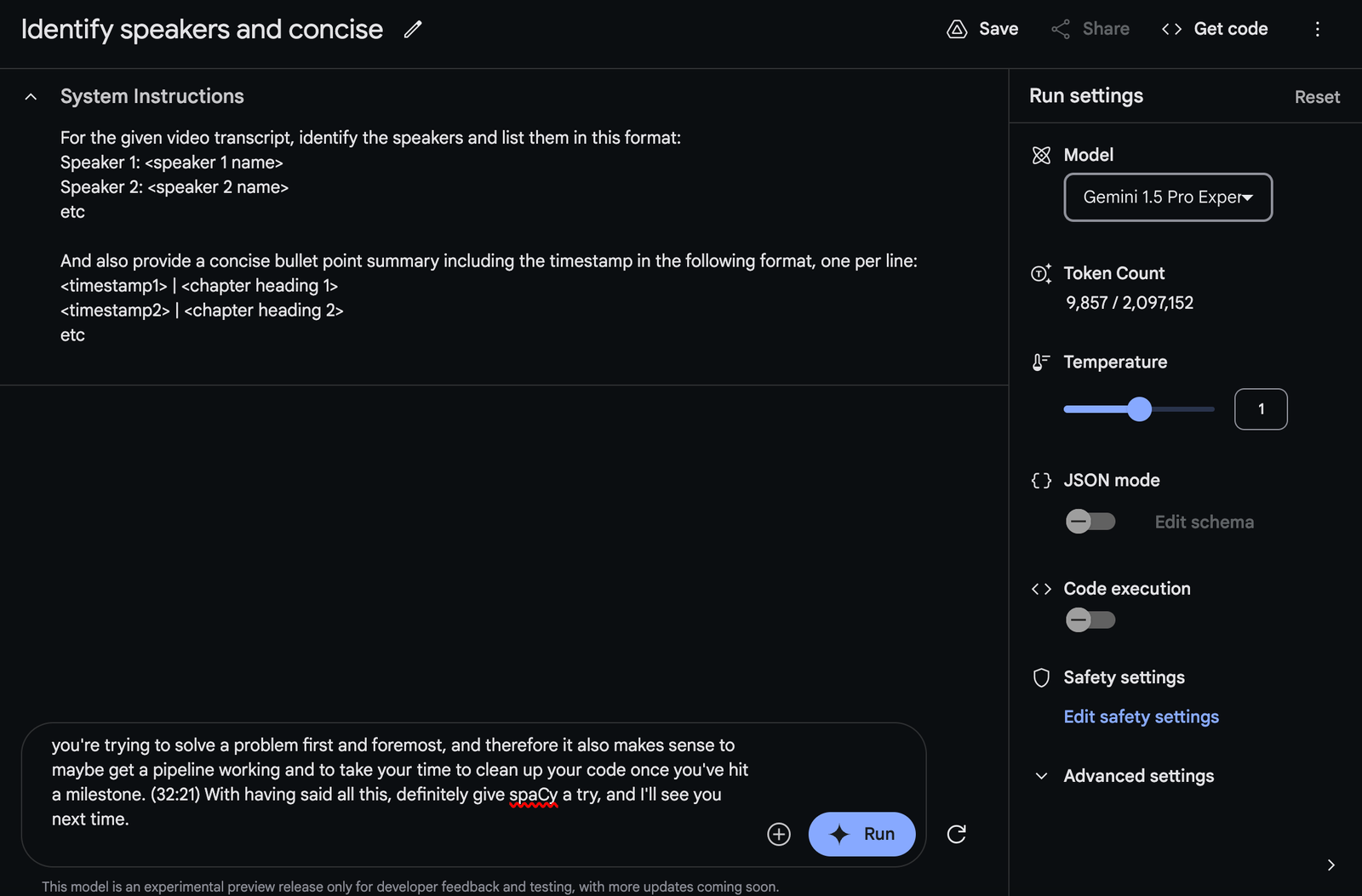
Copy the Markdown response and paste it into a note taking app which supports Markdown.
Here is the response for the current video:
Speaker 1: Vincent
Summary:
0:00 | Introduction and Project Goal (Detecting Programming Languages in Text)
0:35 | Example Use Cases (Recruitment, Stack Overflow)
1:09 | Project Approach (Data Exploration, Python Baseline, spaCy Implementation, Benchmarking)
1:35 | Data Acquisition (Stack Overflow Dataset on Kaggle)
2:25 | Initial Data Exploration using Pandas
3:43 | Challenges of Basic String Matching for "Go" Language Detection
7:07 | Introduction to spaCy and Language Models
7:19 | Loading and Using the 'en-core-web-sm' Model
8:49 | Exploring spaCy Documents and Tokens
9:47 | Token Properties and Linguistic Features
12:11 | Using spaCy to Differentiate "Go" as a Verb vs. Programming Language
13:40 | Improving Code with spaCy and Performance Optimization
18:49 | Utilizing nlp.pipe for Performance Enhancement
20:32 | Disabling Unused Pipeline Components for Further Speed Improvement
22:20 | Benchmarking Strategy using Stack Overflow Tags
23:50 | Implementing Benchmarking Logic with Pandas
27:54 | Benchmark Results and Analysis
30:21 | Project Recap and Future Directions
31:42 | Key Takeaways and Conclusion
Note: Please double check the speakers which were identified by Google AI. If the name isn’t mentioned in the transcript anywhere (that is the speaker does not introduce himself/herself), then Google Gemini sometimes hallucinates the speaker name!
Create an Airtable with the appropriate timestamps
Download the CSV file of the transcript from TurboScribe.
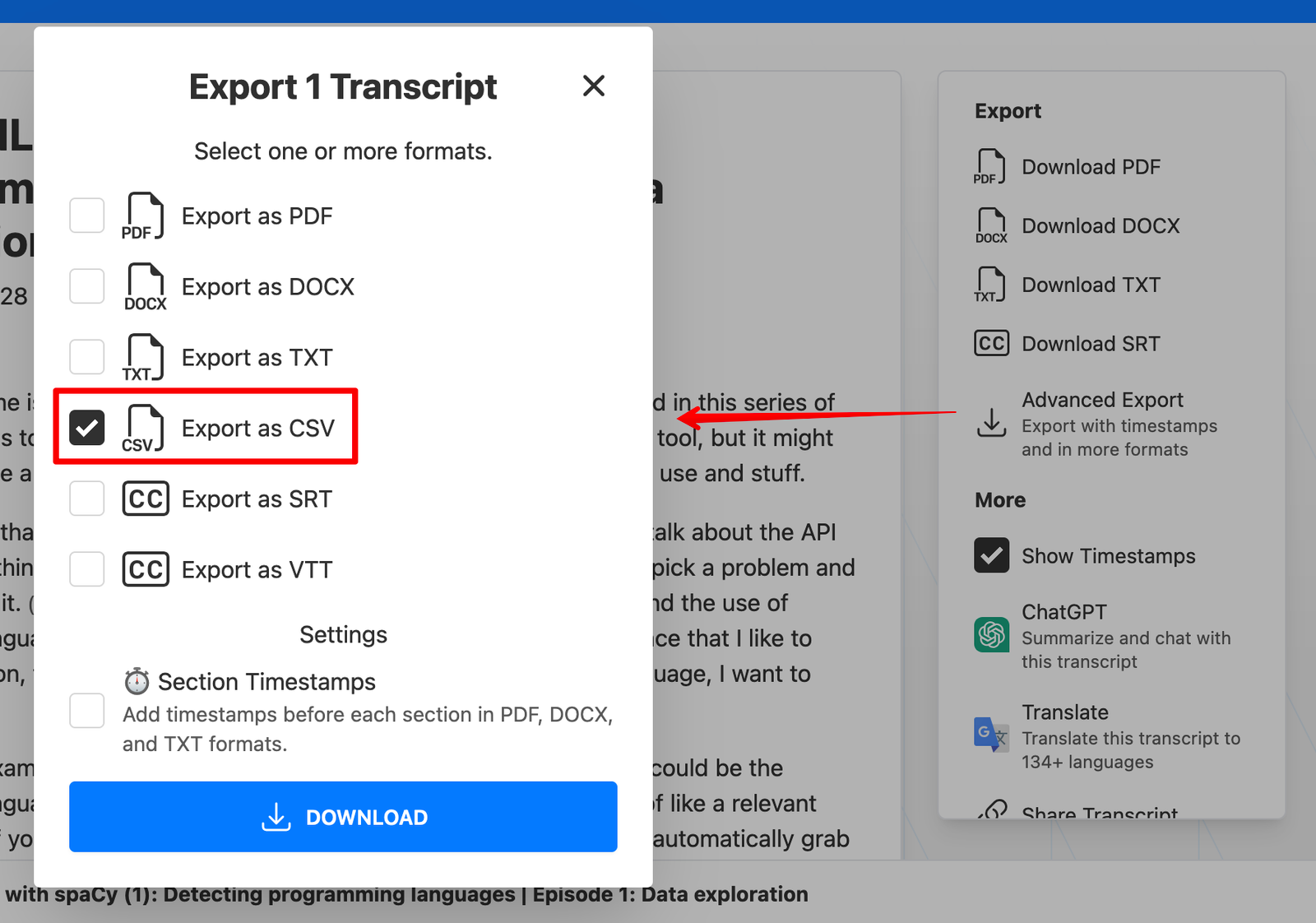
Sign up for Airtable and import the transcript CSV to a new table.
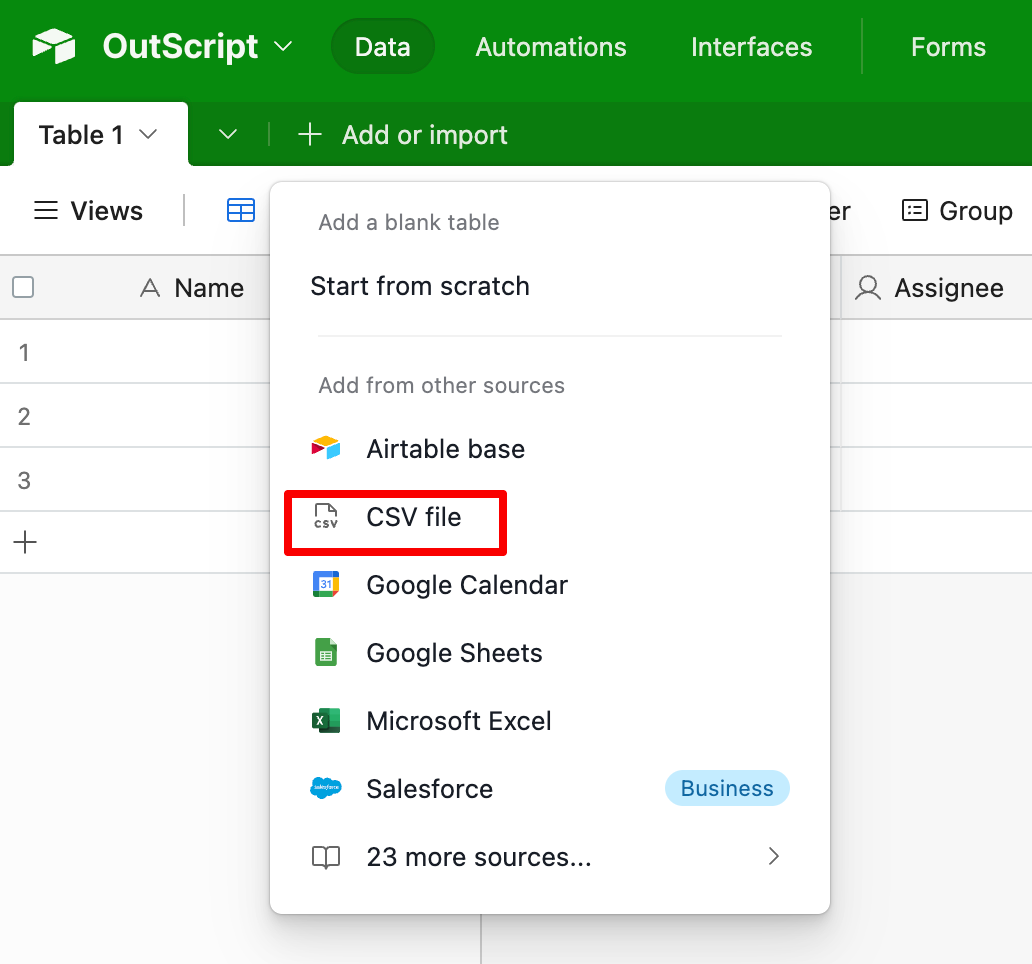
This is what it should look like after the CSV file is imported. Provide a suitable name to the table.
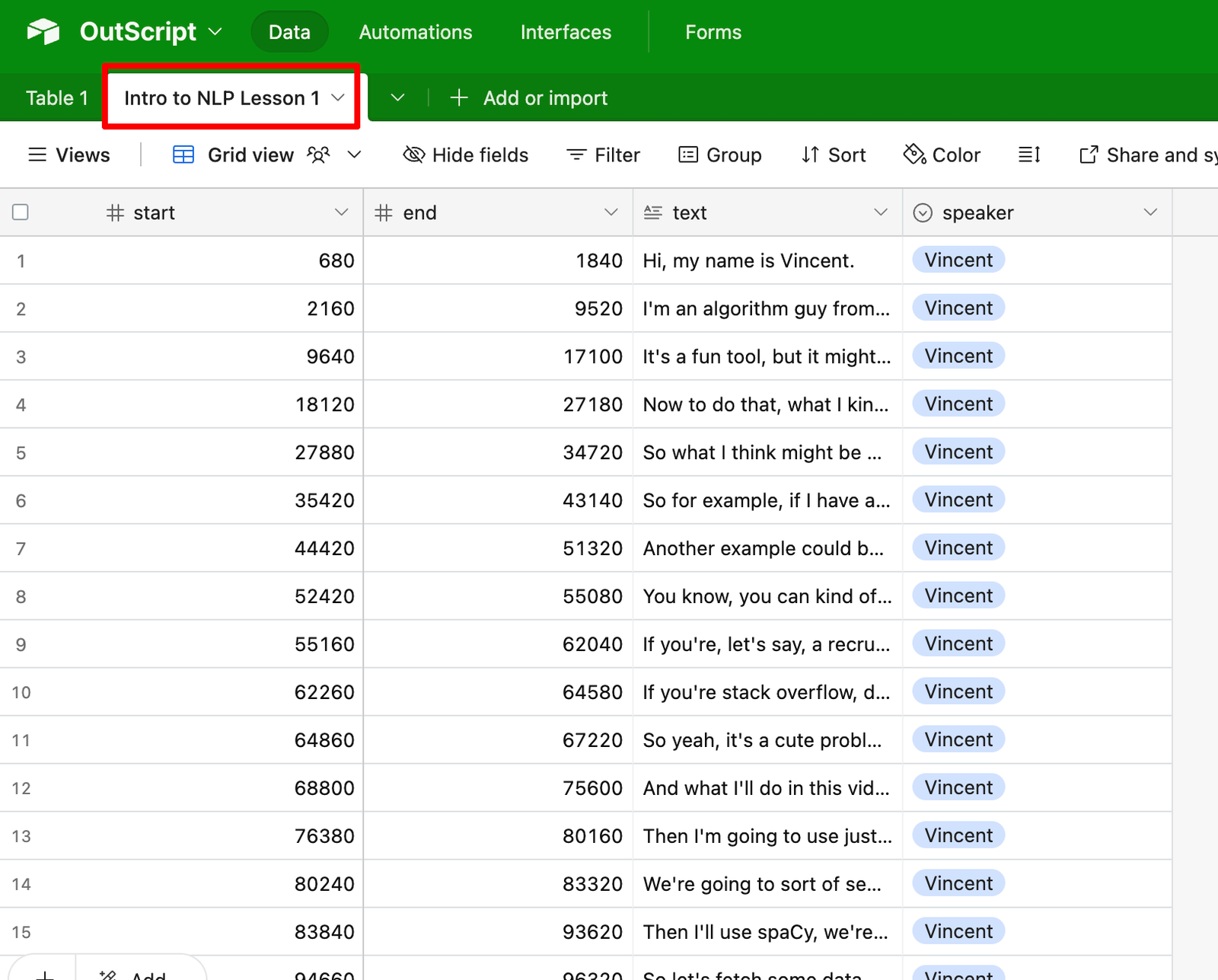
Add a new formula field called start_sec which calculates the start time in seconds.

Add a field called chapter and fill out the chapter subheading in the corresponding row. You can get the seconds by sending another prompt to Google AI studio.
 |  |
Download the CSV file from Airtable.
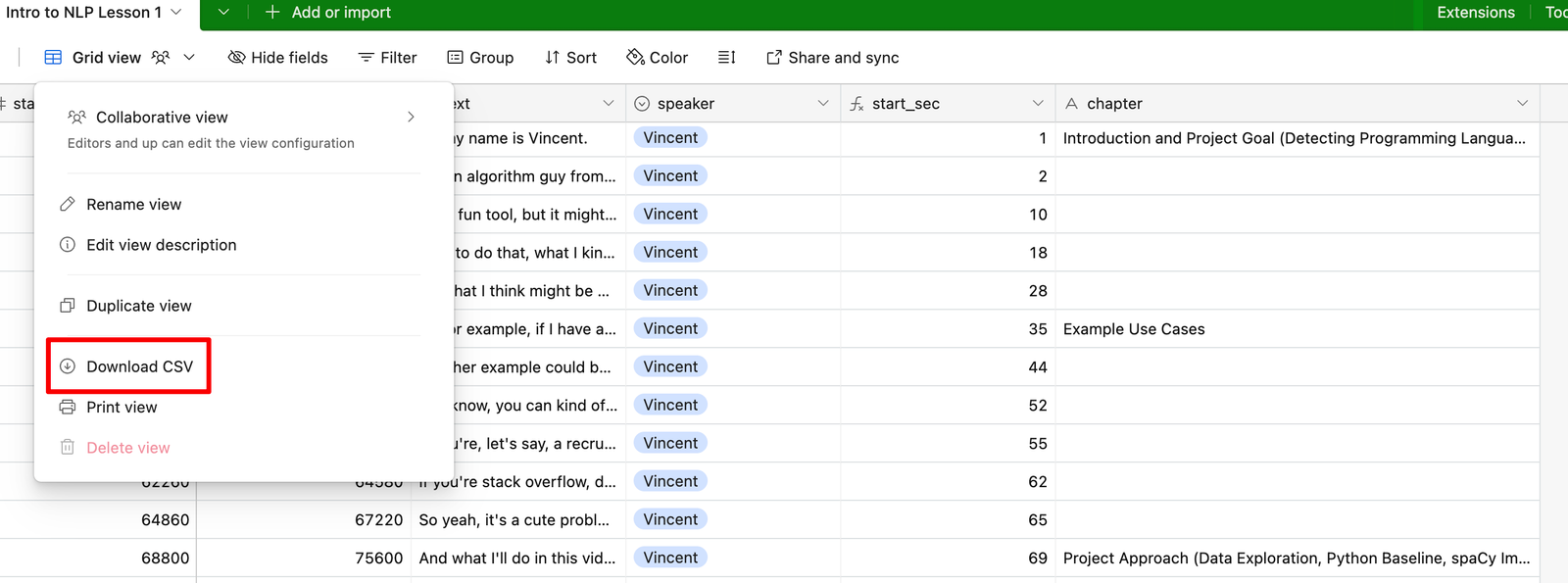
Use the OutScript Creator to get the Markdown
I have built a free tool called the OutScript Creator which will take this CSV file from the previous step and generate an OutScript.
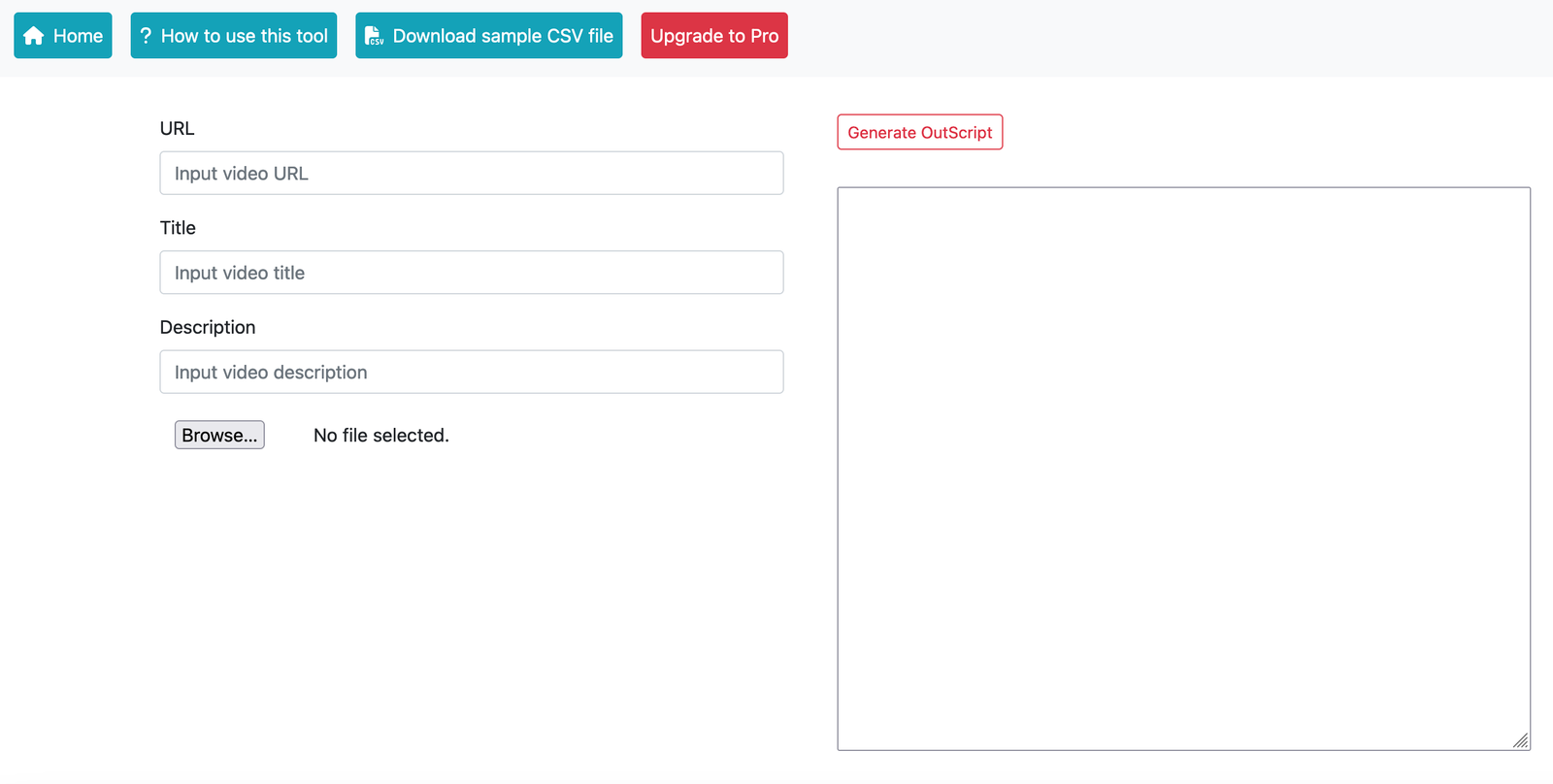
Fill out the URL, Title and Description of the video.
Select the CSV file you downloaded in the previous step which includes the chapter field.
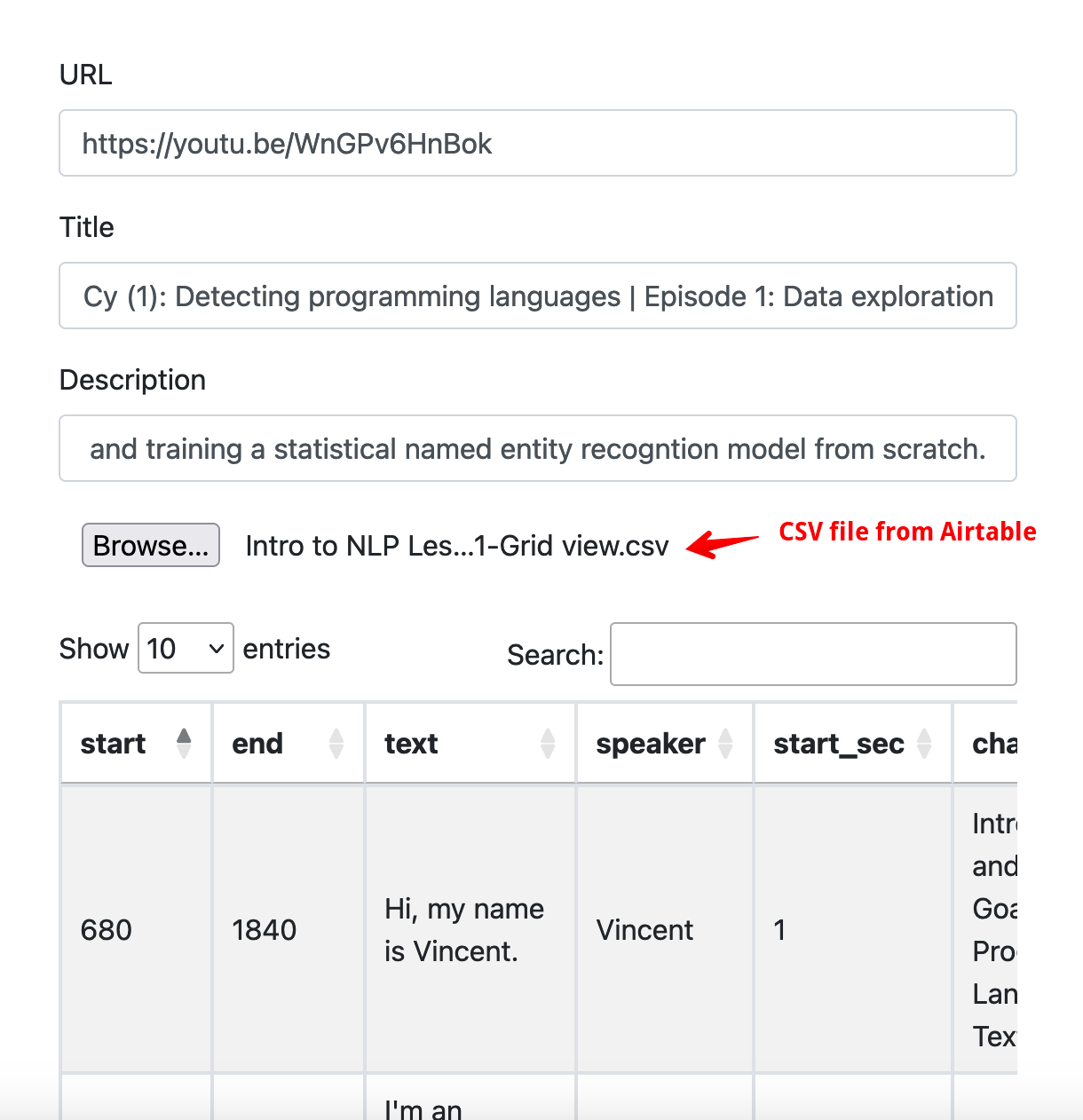
Click on the “Generate OutScript” button and you will see the Markdown in the text area below the button.
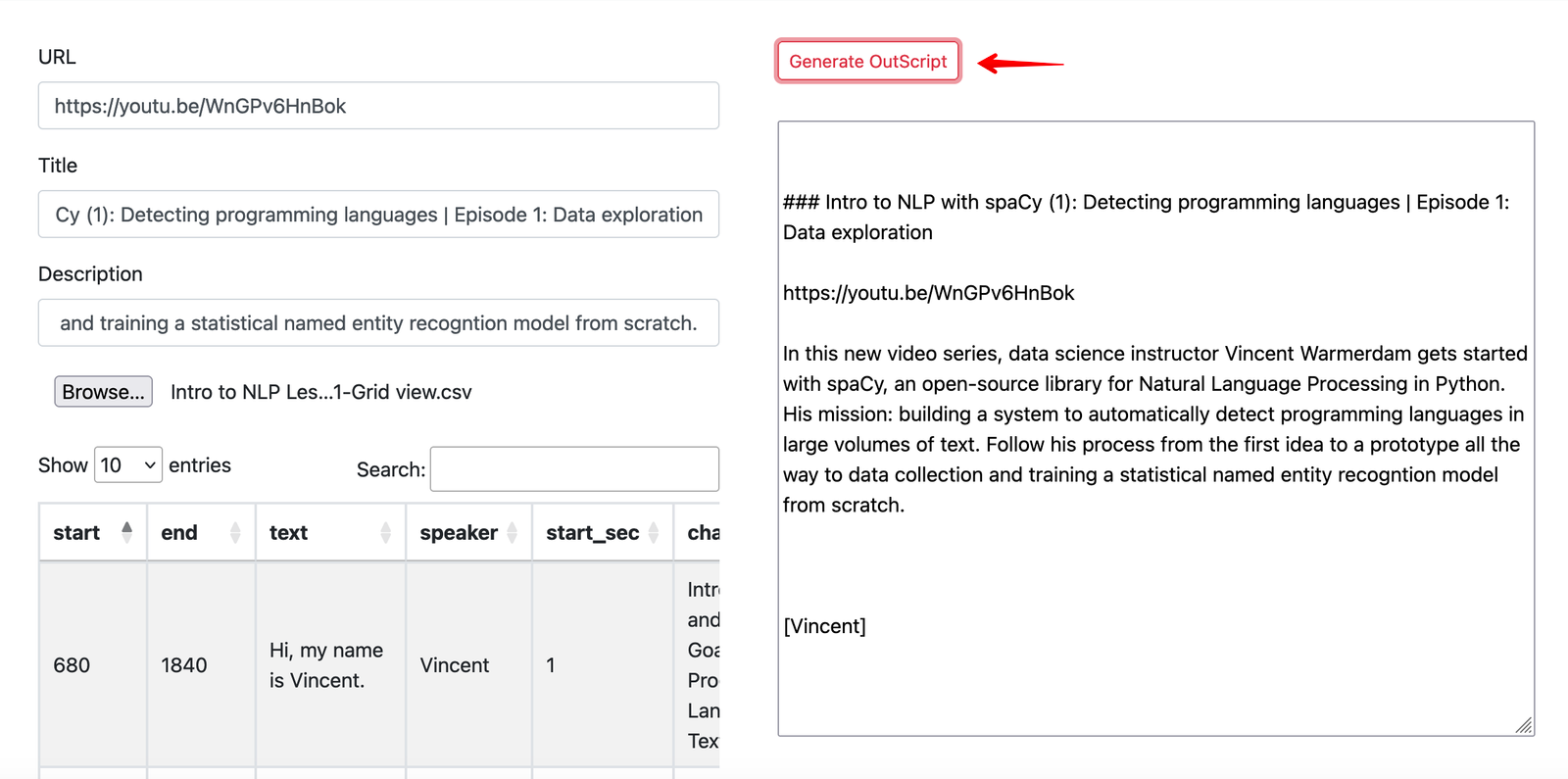
Now copy this Markdown and paste it into some note taking app which supports Markdown.
Automate this step using OutScript Creator Pro
I have created a tool which allows you to skip the manual chapter annotation, and automatically merges the output from Google AI Studio into the transcript at the right locations.
Convert Markdown to HTML and PDF
You can convert any Markdown to PDF using Dilinger.
Paste the Markdown from the previous step into the Dilinger text area.
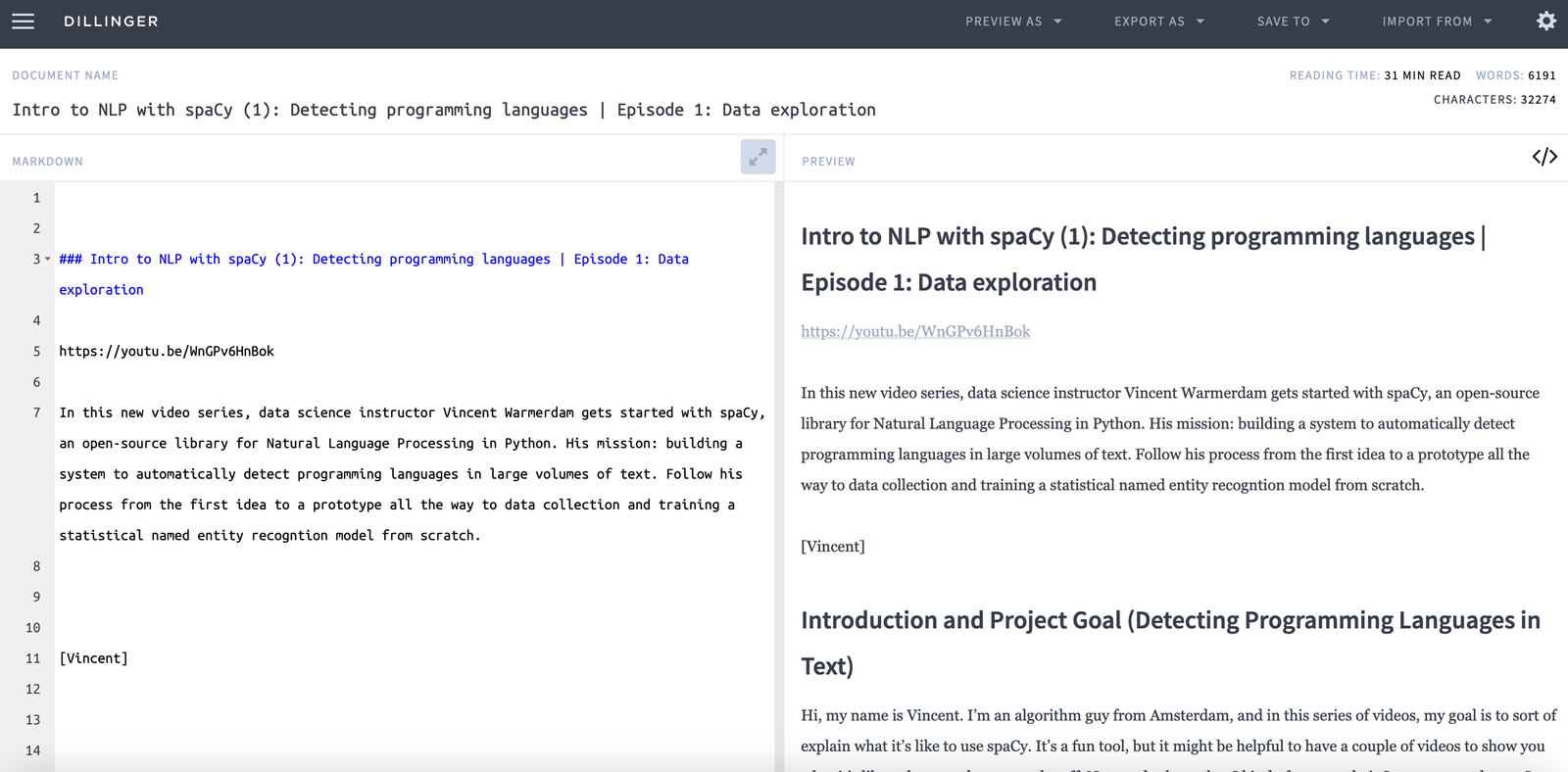
Click on “Export As” > “PDF”
Upload PDF folder to ChatPDF
Once you have all the PDF files for the video within a playlist, sign up for ChatPDF
Create a new folder inside ChatPDF

Upload all the files into a single folder.
You can now ask questions across the contents of all the PDF files in this folder.

Ask questions about the videos (virtual tutor)
The biggest advantage of creating OutScripts in PDF format is that it provides an easy-to-skim file which can be used inside ChatPDF.
Once you upload a set of OutScripts to a single folder in ChatPDF, you can ask questions across the entire folder – in other words, across the entire list of videos.
For example, consider this lesson in the Intro to NLP with spaCy course. It compares rules-based vs statistical approaches in spaCy. This is actually one of the important questions for anyone considering using spaCy.
Suppose you wanted to know if this topic is discussed in the other videos in the playlist.
You can simply ask this question to ChatPDF:
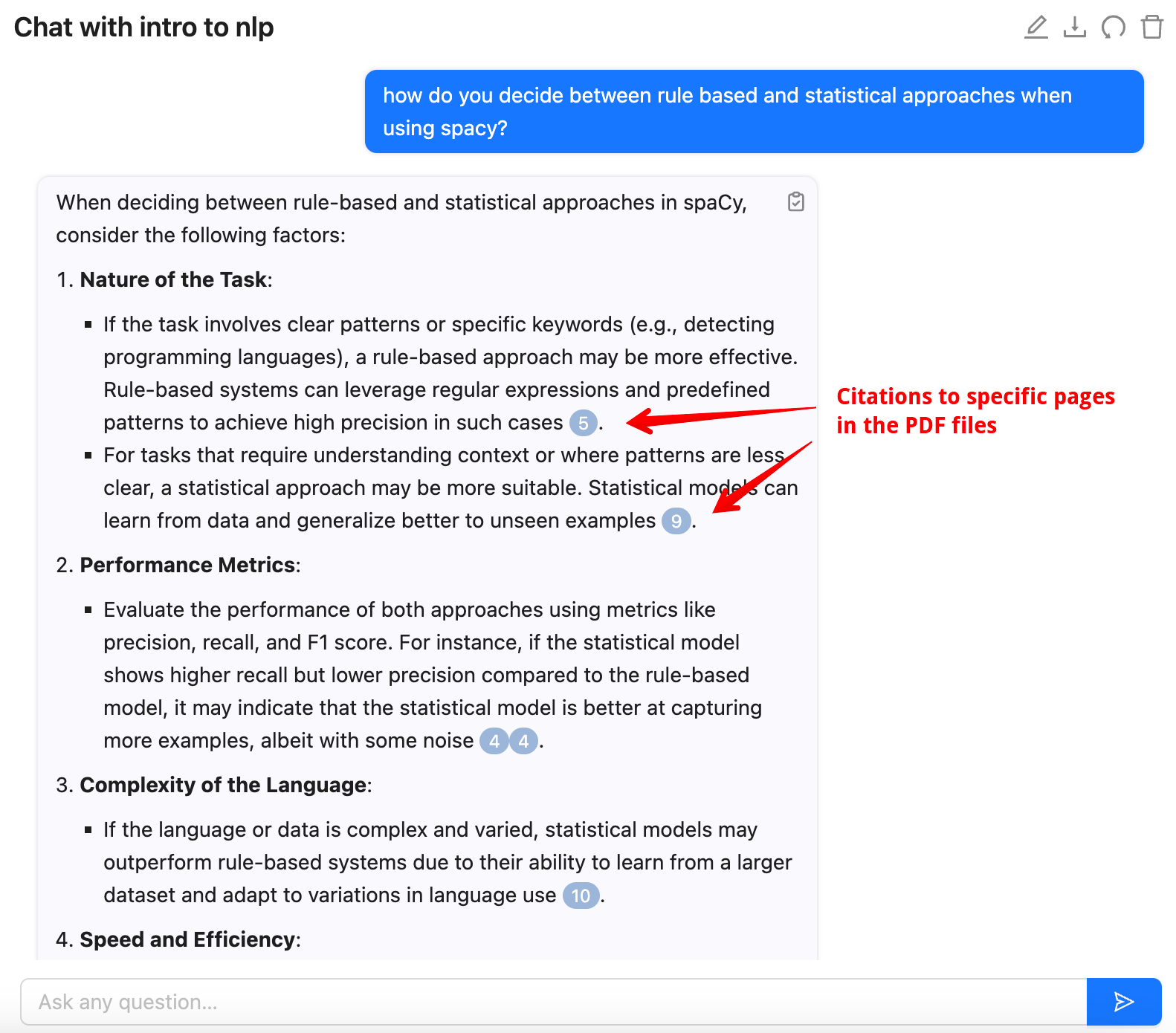
Clicking on the citation opens up the specific PDF page and paragraph.
In this response, most of the citations are from the video which compares rules-based and statistical techniques in spaCy. But there are also a couple of citations to other videos.
Let us click on a citation which is from one of the other videos.

As you can see, you now get a citation to a specific point in the video which explains the summary information in a lot more detail.
You can also see the timestamps and the video URL. (URLs inside the PDFs are not clickable, so you need to copy/paste them into a browser). But you can now watch the video at the specific timestamp if you want a more in-depth understanding of the topic.
In other words, you can now use this system as a virtual tutor to help guide you as you learn a topic.