List of OpenRouter LLMs which support structured outputs
I created this list by calling the API and then extracting the relevant information.
I hope to keep it updated as frequently as possible, but be sure to check the last updated date.
Last updated: August 13, 2025 at 07:02 AM UTC
List of OpenRouter LLMs
| Model Name | Date Added | Input Price ($/M tokens) | Output Price ($/M tokens) | Context Length | Structured Outputs | Response Schema | Reasoning | Include Reasoning | Description |
|---|---|---|---|---|---|---|---|---|---|
| z-ai/glm-4.5v | 2025-08-11 | $0.50 | $1.80 | 65,536 | No | No | Yes | Yes | GLM-4.5V is a vision-language foundation model for multimodal agent applications. Built on a Mixture-of-Experts (MoE) architecture with 106B parameters and 12B activated parameters, it achieves state-of-the-art results in video understanding, image Q&A, OCR, and document parsing, with strong gains in front-end web coding, grounding, and spatial reasoning. It offers a hybrid inference mode: a “thinking mode” for deep reasoning and a “non-thinking mode” for fast responses. Reasoning behavior can be toggled via the `reasoning` `enabled` boolean. [Learn more in our docs](https://openrouter.ai/docs/use-cases/reasoning-tokens#enable-reasoning-with-default-config) |
| ai21/jamba-mini-1.7 | 2025-08-08 | $0.20 | $0.40 | 256,000 | No | Yes | No | No | Jamba Mini 1.7 is a compact and efficient member of the Jamba open model family, incorporating key improvements in grounding and instruction-following while maintaining the benefits of the SSM-Transformer hybrid architecture and 256K context window. Despite its compact size, it delivers accurate, contextually grounded responses and improved steerability. |
| ai21/jamba-large-1.7 | 2025-08-08 | $2.00 | $8.00 | 256,000 | No | Yes | No | No | Jamba Large 1.7 is the latest model in the Jamba open family, offering improvements in grounding, instruction-following, and overall efficiency. Built on a hybrid SSM-Transformer architecture with a 256K context window, it delivers more accurate, contextually grounded responses and better steerability than previous versions. |
| openai/gpt-5-chat | 2025-08-07 | $1.25 | $10.00 | 400,000 | Yes | Yes | Yes | Yes | GPT-5 Chat is designed for advanced, natural, multimodal, and context-aware conversations for enterprise applications. |
| openai/gpt-5 | 2025-08-07 | $1.25 | $10.00 | 400,000 | Yes | Yes | Yes | Yes | GPT-5 is OpenAI’s most advanced model, offering major improvements in reasoning, code quality, and user experience. It is optimized for complex tasks that require step-by-step reasoning, instruction following, and accuracy in high-stakes use cases. It supports test-time routing features and advanced prompt understanding, including user-specified intent like “think hard about this.” Improvements include reductions in hallucination, sycophancy, and better performance in coding, writing, and health-related tasks.
Note that BYOK is required for this model. Set up here: https://openrouter.ai/settings/integrations |
| openai/gpt-5-mini | 2025-08-07 | $0.25 | $2.00 | 400,000 | Yes | Yes | Yes | Yes | GPT-5 Mini is a compact version of GPT-5, designed to handle lighter-weight reasoning tasks. It provides the same instruction-following and safety-tuning benefits as GPT-5, but with reduced latency and cost. GPT-5 Mini is the successor to OpenAI’s o4-mini model. |
| openai/gpt-5-nano | 2025-08-07 | $0.05 | $0.40 | 400,000 | Yes | Yes | Yes | Yes | GPT-5-Nano is the smallest and fastest variant in the GPT-5 system, optimized for developer tools, rapid interactions, and ultra-low latency environments. While limited in reasoning depth compared to its larger counterparts, it retains key instruction-following and safety features. It is the successor to GPT-4.1-nano and offers a lightweight option for cost-sensitive or real-time applications. |
| openai/gpt-oss-120b | 2025-08-05 | $0.07 | $0.29 | 131,072 | Yes | Yes | Yes | Yes | gpt-oss-120b is an open-weight, 117B-parameter Mixture-of-Experts (MoE) language model from OpenAI designed for high-reasoning, agentic, and general-purpose production use cases. It activates 5.1B parameters per forward pass and is optimized to run on a single H100 GPU with native MXFP4 quantization. The model supports configurable reasoning depth, full chain-of-thought access, and native tool use, including function calling, browsing, and structured output generation. |
| openai/gpt-oss-20b:free | 2025-08-05 | $0.00 | $0.00 | 131,072 | Yes | Yes | Yes | Yes | gpt-oss-20b is an open-weight 21B parameter model released by OpenAI under the Apache 2.0 license. It uses a Mixture-of-Experts (MoE) architecture with 3.6B active parameters per forward pass, optimized for lower-latency inference and deployability on consumer or single-GPU hardware. The model is trained in OpenAI’s Harmony response format and supports reasoning level configuration, fine-tuning, and agentic capabilities including function calling, tool use, and structured outputs. |
| openai/gpt-oss-20b | 2025-08-05 | $0.04 | $0.16 | 131,072 | Yes | Yes | Yes | Yes | gpt-oss-20b is an open-weight 21B parameter model released by OpenAI under the Apache 2.0 license. It uses a Mixture-of-Experts (MoE) architecture with 3.6B active parameters per forward pass, optimized for lower-latency inference and deployability on consumer or single-GPU hardware. The model is trained in OpenAI’s Harmony response format and supports reasoning level configuration, fine-tuning, and agentic capabilities including function calling, tool use, and structured outputs. |
| anthropic/claude-opus-4.1 | 2025-08-05 | $15.00 | $75.00 | 200,000 | No | No | Yes | Yes | Claude Opus 4.1 is an updated version of Anthropic’s flagship model, offering improved performance in coding, reasoning, and agentic tasks. It achieves 74.5% on SWE-bench Verified and shows notable gains in multi-file code refactoring, debugging precision, and detail-oriented reasoning. The model supports extended thinking up to 64K tokens and is optimized for tasks involving research, data analysis, and tool-assisted reasoning. |
| mistralai/codestral-2508 | 2025-08-02 | $0.30 | $0.90 | 256,000 | Yes | Yes | No | No | Mistral’s cutting-edge language model for coding released end of July 2025. Codestral specializes in low-latency, high-frequency tasks such as fill-in-the-middle (FIM), code correction and test generation.
[Blog Post](https://mistral.ai/news/codestral-25-08) |
| qwen/qwen3-30b-a3b-instruct-2507 | 2025-07-29 | $0.20 | $0.80 | 131,072 | No | Yes | No | No | Qwen3-30B-A3B-Instruct-2507 is a 30.5B-parameter mixture-of-experts language model from Qwen, with 3.3B active parameters per inference. It operates in non-thinking mode and is designed for high-quality instruction following, multilingual understanding, and agentic tool use. Post-trained on instruction data, it demonstrates competitive performance across reasoning (AIME, ZebraLogic), coding (MultiPL-E, LiveCodeBench), and alignment (IFEval, WritingBench) benchmarks. It outperforms its non-instruct variant on subjective and open-ended tasks while retaining strong factual and coding performance. |
| z-ai/glm-4.5 | 2025-07-26 | $0.20 | $0.80 | 98,304 | No | Yes | Yes | Yes | GLM-4.5 is our latest flagship foundation model, purpose-built for agent-based applications. It leverages a Mixture-of-Experts (MoE) architecture and supports a context length of up to 128k tokens. GLM-4.5 delivers significantly enhanced capabilities in reasoning, code generation, and agent alignment. It supports a hybrid inference mode with two options, a “thinking mode” designed for complex reasoning and tool use, and a “non-thinking mode” optimized for instant responses. Users can control the reasoning behaviour with the `reasoning` `enabled` boolean. [Learn more in our docs](https://openrouter.ai/docs/use-cases/reasoning-tokens#enable-reasoning-with-default-config) |
| z-ai/glm-4.5-air:free | 2025-07-26 | $0.00 | $0.00 | 131,072 | No | No | Yes | Yes | GLM-4.5-Air is the lightweight variant of our latest flagship model family, also purpose-built for agent-centric applications. Like GLM-4.5, it adopts the Mixture-of-Experts (MoE) architecture but with a more compact parameter size. GLM-4.5-Air also supports hybrid inference modes, offering a “thinking mode” for advanced reasoning and tool use, and a “non-thinking mode” for real-time interaction. Users can control the reasoning behaviour with the `reasoning` `enabled` boolean. [Learn more in our docs](https://openrouter.ai/docs/use-cases/reasoning-tokens#enable-reasoning-with-default-config) |
| z-ai/glm-4.5-air | 2025-07-26 | $0.20 | $1.10 | 131,072 | No | Yes | Yes | Yes | GLM-4.5-Air is the lightweight variant of our latest flagship model family, also purpose-built for agent-centric applications. Like GLM-4.5, it adopts the Mixture-of-Experts (MoE) architecture but with a more compact parameter size. GLM-4.5-Air also supports hybrid inference modes, offering a “thinking mode” for advanced reasoning and tool use, and a “non-thinking mode” for real-time interaction. Users can control the reasoning behaviour with the `reasoning` `enabled` boolean. [Learn more in our docs](https://openrouter.ai/docs/use-cases/reasoning-tokens#enable-reasoning-with-default-config) |
| qwen/qwen3-235b-a22b-thinking-2507 | 2025-07-25 | $0.08 | $0.31 | 262,144 | No | Yes | Yes | Yes | Qwen3-235B-A22B-Thinking-2507 is a high-performance, open-weight Mixture-of-Experts (MoE) language model optimized for complex reasoning tasks. It activates 22B of its 235B parameters per forward pass and natively supports up to 262,144 tokens of context. This “thinking-only” variant enhances structured logical reasoning, mathematics, science, and long-form generation, showing strong benchmark performance across AIME, SuperGPQA, LiveCodeBench, and MMLU-Redux. It enforces a special reasoning mode () and is designed for high-token outputs (up to 81,920 tokens) in challenging domains.
The model is instruction-tuned and excels at step-by-step reasoning, tool use, agentic workflows, and multilingual tasks. This release represents the most capable open-source variant in the Qwen3-235B series, surpassing many closed models in structured reasoning use cases. |
| z-ai/glm-4-32b | 2025-07-24 | $0.10 | $0.10 | 128,000 | No | No | No | No | GLM 4 32B is a cost-effective foundation language model.
It can efficiently perform complex tasks and has significantly enhanced capabilities in tool use, online search, and code-related intelligent tasks.
It is made by the same lab behind the thudm models. |
| qwen/qwen3-coder:free | 2025-07-23 | $0.00 | $0.00 | 262,144 | No | No | No | No | Qwen3-Coder-480B-A35B-Instruct is a Mixture-of-Experts (MoE) code generation model developed by the Qwen team. It is optimized for agentic coding tasks such as function calling, tool use, and long-context reasoning over repositories. The model features 480 billion total parameters, with 35 billion active per forward pass (8 out of 160 experts).
Pricing for the Alibaba endpoints varies by context length. Once a request is greater than 128k input tokens, the higher pricing is used. |
| qwen/qwen3-coder | 2025-07-23 | $0.20 | $0.80 | 262,144 | Yes | Yes | No | No | Qwen3-Coder-480B-A35B-Instruct is a Mixture-of-Experts (MoE) code generation model developed by the Qwen team. It is optimized for agentic coding tasks such as function calling, tool use, and long-context reasoning over repositories. The model features 480 billion total parameters, with 35 billion active per forward pass (8 out of 160 experts).
Pricing for the Alibaba endpoints varies by context length. Once a request is greater than 128k input tokens, the higher pricing is used. |
| bytedance/ui-tars-1.5-7b | 2025-07-22 | $0.10 | $0.20 | 128,000 | No | No | No | No | UI-TARS-1.5 is a multimodal vision-language agent optimized for GUI-based environments, including desktop interfaces, web browsers, mobile systems, and games. Built by ByteDance, it builds upon the UI-TARS framework with reinforcement learning-based reasoning, enabling robust action planning and execution across virtual interfaces.
This model achieves state-of-the-art results on a range of interactive and grounding benchmarks, including OSworld, WebVoyager, AndroidWorld, and ScreenSpot. It also demonstrates perfect task completion across diverse Poki games and outperforms prior models in Minecraft agent tasks. UI-TARS-1.5 supports thought decomposition during inference and shows strong scaling across variants, with the 1.5 version notably exceeding the performance of earlier 72B and 7B checkpoints. |
| google/gemini-2.5-flash-lite | 2025-07-22 | $0.10 | $0.40 | 1,048,576 | Yes | Yes | Yes | Yes | Gemini 2.5 Flash-Lite is a lightweight reasoning model in the Gemini 2.5 family, optimized for ultra-low latency and cost efficiency. It offers improved throughput, faster token generation, and better performance across common benchmarks compared to earlier Flash models. By default, “thinking” (i.e. multi-pass reasoning) is disabled to prioritize speed, but developers can enable it via the [Reasoning API parameter](https://openrouter.ai/docs/use-cases/reasoning-tokens) to selectively trade off cost for intelligence. |
| qwen/qwen3-235b-a22b-2507 | 2025-07-21 | $0.08 | $0.31 | 262,144 | Yes | Yes | No | No | Qwen3-235B-A22B-Instruct-2507 is a multilingual, instruction-tuned mixture-of-experts language model based on the Qwen3-235B architecture, with 22B active parameters per forward pass. It is optimized for general-purpose text generation, including instruction following, logical reasoning, math, code, and tool usage. The model supports a native 262K context length and does not implement “thinking mode” ( |
| switchpoint/router | 2025-07-12 | $0.85 | $3.40 | 131,072 | No | No | Yes | Yes | Switchpoint AI’s router instantly analyzes your request and directs it to the optimal AI from an ever-evolving library.
As the world of LLMs advances, our router gets smarter, ensuring you always benefit from the industry’s newest models without changing your workflow.
This model is configured for a simple, flat rate per response here on OpenRouter. It’s powered by the full routing engine from [Switchpoint AI](https://www.switchpoint.dev). |
| moonshotai/kimi-k2:free | 2025-07-12 | $0.00 | $0.00 | 32,768 | No | No | No | No | Kimi K2 Instruct is a large-scale Mixture-of-Experts (MoE) language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion active per forward pass. It is optimized for agentic capabilities, including advanced tool use, reasoning, and code synthesis. Kimi K2 excels across a broad range of benchmarks, particularly in coding (LiveCodeBench, SWE-bench), reasoning (ZebraLogic, GPQA), and tool-use (Tau2, AceBench) tasks. It supports long-context inference up to 128K tokens and is designed with a novel training stack that includes the MuonClip optimizer for stable large-scale MoE training. |
| moonshotai/kimi-k2 | 2025-07-12 | $0.14 | $2.49 | 63,000 | Yes | Yes | No | No | Kimi K2 Instruct is a large-scale Mixture-of-Experts (MoE) language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion active per forward pass. It is optimized for agentic capabilities, including advanced tool use, reasoning, and code synthesis. Kimi K2 excels across a broad range of benchmarks, particularly in coding (LiveCodeBench, SWE-bench), reasoning (ZebraLogic, GPQA), and tool-use (Tau2, AceBench) tasks. It supports long-context inference up to 128K tokens and is designed with a novel training stack that includes the MuonClip optimizer for stable large-scale MoE training. |
| thudm/glm-4.1v-9b-thinking | 2025-07-11 | $0.04 | $0.14 | 65,536 | No | No | Yes | Yes | GLM-4.1V-9B-Thinking is a 9B parameter vision-language model developed by THUDM, based on the GLM-4-9B foundation. It introduces a reasoning-centric “thinking paradigm” enhanced with reinforcement learning to improve multimodal reasoning, long-context understanding (up to 64K tokens), and complex problem solving. It achieves state-of-the-art performance among models in its class, outperforming even larger models like Qwen-2.5-VL-72B on a majority of benchmark tasks. |
| mistralai/devstral-medium | 2025-07-10 | $0.40 | $2.00 | 131,072 | Yes | Yes | No | No | Devstral Medium is a high-performance code generation and agentic reasoning model developed jointly by Mistral AI and All Hands AI. Positioned as a step up from Devstral Small, it achieves 61.6% on SWE-Bench Verified, placing it ahead of Gemini 2.5 Pro and GPT-4.1 in code-related tasks, at a fraction of the cost. It is designed for generalization across prompt styles and tool use in code agents and frameworks.
Devstral Medium is available via API only (not open-weight), and supports enterprise deployment on private infrastructure, with optional fine-tuning capabilities. |
| mistralai/devstral-small | 2025-07-10 | $0.07 | $0.28 | 128,000 | Yes | Yes | No | No | Devstral Small 1.1 is a 24B parameter open-weight language model for software engineering agents, developed by Mistral AI in collaboration with All Hands AI. Finetuned from Mistral Small 3.1 and released under the Apache 2.0 license, it features a 128k token context window and supports both Mistral-style function calling and XML output formats.
Designed for agentic coding workflows, Devstral Small 1.1 is optimized for tasks such as codebase exploration, multi-file edits, and integration into autonomous development agents like OpenHands and Cline. It achieves 53.6% on SWE-Bench Verified, surpassing all other open models on this benchmark, while remaining lightweight enough to run on a single 4090 GPU or Apple silicon machine. The model uses a Tekken tokenizer with a 131k vocabulary and is deployable via vLLM, Transformers, Ollama, LM Studio, and other OpenAI-compatible runtimes.
|
| cognitivecomputations/dolphin-mistral-24b-venice-edition:free | 2025-07-10 | $0.00 | $0.00 | 32,768 | Yes | Yes | No | No | Venice Uncensored Dolphin Mistral 24B Venice Edition is a fine-tuned variant of Mistral-Small-24B-Instruct-2501, developed by dphn.ai in collaboration with Venice.ai. This model is designed as an “uncensored” instruct-tuned LLM, preserving user control over alignment, system prompts, and behavior. Intended for advanced and unrestricted use cases, Venice Uncensored emphasizes steerability and transparent behavior, removing default safety and alignment layers typically found in mainstream assistant models. |
| x-ai/grok-4 | 2025-07-10 | $3.00 | $15.00 | 256,000 | Yes | Yes | Yes | Yes | Grok 4 is xAI’s latest reasoning model with a 256k context window. It supports parallel tool calling, structured outputs, and both image and text inputs. Note that reasoning is not exposed, reasoning cannot be disabled, and the reasoning effort cannot be specified. Pricing increases once the total tokens in a given request is greater than 128k tokens. See more details on the [xAI docs](https://docs.x.ai/docs/models/grok-4-0709) |
| google/gemma-3n-e2b-it:free | 2025-07-09 | $0.00 | $0.00 | 8,192 | No | Yes | No | No | Gemma 3n E2B IT is a multimodal, instruction-tuned model developed by Google DeepMind, designed to operate efficiently at an effective parameter size of 2B while leveraging a 6B architecture. Based on the MatFormer architecture, it supports nested submodels and modular composition via the Mix-and-Match framework. Gemma 3n models are optimized for low-resource deployment, offering 32K context length and strong multilingual and reasoning performance across common benchmarks. This variant is trained on a diverse corpus including code, math, web, and multimodal data. |
| tencent/hunyuan-a13b-instruct:free | 2025-07-08 | $0.00 | $0.00 | 32,768 | No | No | Yes | Yes | Hunyuan-A13B is a 13B active parameter Mixture-of-Experts (MoE) language model developed by Tencent, with a total parameter count of 80B and support for reasoning via Chain-of-Thought. It offers competitive benchmark performance across mathematics, science, coding, and multi-turn reasoning tasks, while maintaining high inference efficiency via Grouped Query Attention (GQA) and quantization support (FP8, GPTQ, etc.). |
| tencent/hunyuan-a13b-instruct | 2025-07-08 | $0.03 | $0.03 | 32,768 | No | No | Yes | Yes | Hunyuan-A13B is a 13B active parameter Mixture-of-Experts (MoE) language model developed by Tencent, with a total parameter count of 80B and support for reasoning via Chain-of-Thought. It offers competitive benchmark performance across mathematics, science, coding, and multi-turn reasoning tasks, while maintaining high inference efficiency via Grouped Query Attention (GQA) and quantization support (FP8, GPTQ, etc.). |
| tngtech/deepseek-r1t2-chimera:free | 2025-07-08 | $0.00 | $0.00 | 163,840 | No | No | Yes | Yes | DeepSeek-TNG-R1T2-Chimera is the second-generation Chimera model from TNG Tech. It is a 671 B-parameter mixture-of-experts text-generation model assembled from DeepSeek-AI’s R1-0528, R1, and V3-0324 checkpoints with an Assembly-of-Experts merge. The tri-parent design yields strong reasoning performance while running roughly 20 % faster than the original R1 and more than 2× faster than R1-0528 under vLLM, giving a favorable cost-to-intelligence trade-off. The checkpoint supports contexts up to 60 k tokens in standard use (tested to ~130 k) and maintains consistent |
| morph/morph-v3-large | 2025-07-07 | $0.90 | $1.90 | 81,920 | No | No | No | No | Morph’s high-accuracy apply model for complex code edits. 2000+ tokens/sec with 98% accuracy for precise code transformations. |
| morph/morph-v3-fast | 2025-07-07 | $0.90 | $1.90 | 81,920 | No | No | No | No | Morph’s fastest apply model for code edits. 4500+ tokens/sec with 96% accuracy for rapid code transformations. |
| baidu/ernie-4.5-300b-a47b | 2025-06-30 | $0.28 | $1.10 | 123,000 | No | No | No | No | ERNIE-4.5-300B-A47B is a 300B parameter Mixture-of-Experts (MoE) language model developed by Baidu as part of the ERNIE 4.5 series. It activates 47B parameters per token and supports text generation in both English and Chinese. Optimized for high-throughput inference and efficient scaling, it uses a heterogeneous MoE structure with advanced routing and quantization strategies, including FP8 and 2-bit formats. This version is fine-tuned for language-only tasks and supports reasoning, tool parameters, and extended context lengths up to 131k tokens. Suitable for general-purpose LLM applications with high reasoning and throughput demands. |
| thedrummer/anubis-70b-v1.1 | 2025-06-29 | $0.40 | $0.70 | 16,384 | Yes | Yes | No | No | TheDrummer’s Anubis v1.1 is an unaligned, creative Llama 3.3 70B model focused on providing character-driven roleplay & stories. It excels at gritty, visceral prose, unique character adherence, and coherent narratives, while maintaining the instruction following Llama 3.3 70B is known for. |
| inception/mercury | 2025-06-27 | $0.25 | $1.00 | 128,000 | Yes | Yes | No | No | Mercury is the first diffusion large language model (dLLM). Applying a breakthrough discrete diffusion approach, the model runs 5-10x faster than even speed optimized models like GPT-4.1 Nano and Claude 3.5 Haiku while matching their performance. Mercury’s speed enables developers to provide responsive user experiences, including with voice agents, search interfaces, and chatbots. Read more in the blog post here. |
| mistralai/mistral-small-3.2-24b-instruct:free | 2025-06-20 | $0.00 | $0.00 | 131,072 | Yes | No | No | No | Mistral-Small-3.2-24B-Instruct-2506 is an updated 24B parameter model from Mistral optimized for instruction following, repetition reduction, and improved function calling. Compared to the 3.1 release, version 3.2 significantly improves accuracy on WildBench and Arena Hard, reduces infinite generations, and delivers gains in tool use and structured output tasks.
It supports image and text inputs with structured outputs, function/tool calling, and strong performance across coding (HumanEval+, MBPP), STEM (MMLU, MATH, GPQA), and vision benchmarks (ChartQA, DocVQA). |
| mistralai/mistral-small-3.2-24b-instruct | 2025-06-20 | $0.02 | $0.08 | 131,072 | Yes | Yes | No | No | Mistral-Small-3.2-24B-Instruct-2506 is an updated 24B parameter model from Mistral optimized for instruction following, repetition reduction, and improved function calling. Compared to the 3.1 release, version 3.2 significantly improves accuracy on WildBench and Arena Hard, reduces infinite generations, and delivers gains in tool use and structured output tasks.
It supports image and text inputs with structured outputs, function/tool calling, and strong performance across coding (HumanEval+, MBPP), STEM (MMLU, MATH, GPQA), and vision benchmarks (ChartQA, DocVQA). |
| minimax/minimax-m1 | 2025-06-18 | $0.30 | $1.65 | 1,000,000 | Yes | No | Yes | Yes | MiniMax-M1 is a large-scale, open-weight reasoning model designed for extended context and high-efficiency inference. It leverages a hybrid Mixture-of-Experts (MoE) architecture paired with a custom “lightning attention” mechanism, allowing it to process long sequences—up to 1 million tokens—while maintaining competitive FLOP efficiency. With 456 billion total parameters and 45.9B active per token, this variant is optimized for complex, multi-step reasoning tasks.
Trained via a custom reinforcement learning pipeline (CISPO), M1 excels in long-context understanding, software engineering, agentic tool use, and mathematical reasoning. Benchmarks show strong performance across FullStackBench, SWE-bench, MATH, GPQA, and TAU-Bench, often outperforming other open models like DeepSeek R1 and Qwen3-235B. |
| google/gemini-2.5-flash-lite-preview-06-17 | 2025-06-17 | $0.10 | $0.40 | 1,048,576 | Yes | Yes | Yes | Yes | Gemini 2.5 Flash-Lite is a lightweight reasoning model in the Gemini 2.5 family, optimized for ultra-low latency and cost efficiency. It offers improved throughput, faster token generation, and better performance across common benchmarks compared to earlier Flash models. By default, “thinking” (i.e. multi-pass reasoning) is disabled to prioritize speed, but developers can enable it via the [Reasoning API parameter](https://openrouter.ai/docs/use-cases/reasoning-tokens) to selectively trade off cost for intelligence. |
| google/gemini-2.5-flash | 2025-06-17 | $0.30 | $2.50 | 1,048,576 | Yes | Yes | Yes | Yes | Gemini 2.5 Flash is Google’s state-of-the-art workhorse model, specifically designed for advanced reasoning, coding, mathematics, and scientific tasks. It includes built-in “thinking” capabilities, enabling it to provide responses with greater accuracy and nuanced context handling.
Additionally, Gemini 2.5 Flash is configurable through the “max tokens for reasoning” parameter, as described in the documentation (https://openrouter.ai/docs/use-cases/reasoning-tokens#max-tokens-for-reasoning). |
| google/gemini-2.5-pro | 2025-06-17 | $1.25 | $10.00 | 1,048,576 | Yes | Yes | Yes | Yes | Gemini 2.5 Pro is Google’s state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. It employs “thinking” capabilities, enabling it to reason through responses with enhanced accuracy and nuanced context handling. Gemini 2.5 Pro achieves top-tier performance on multiple benchmarks, including first-place positioning on the LMArena leaderboard, reflecting superior human-preference alignment and complex problem-solving abilities. |
| moonshotai/kimi-dev-72b:free | 2025-06-17 | $0.00 | $0.00 | 131,072 | No | No | Yes | Yes | Kimi-Dev-72B is an open-source large language model fine-tuned for software engineering and issue resolution tasks. Based on Qwen2.5-72B, it is optimized using large-scale reinforcement learning that applies code patches in real repositories and validates them via full test suite execution—rewarding only correct, robust completions. The model achieves 60.4% on SWE-bench Verified, setting a new benchmark among open-source models for software bug fixing and code reasoning. |
| openai/o3-pro | 2025-06-11 | $20.00 | $80.00 | 200,000 | Yes | Yes | Yes | Yes | The o-series of models are trained with reinforcement learning to think before they answer and perform complex reasoning. The o3-pro model uses more compute to think harder and provide consistently better answers.
Note that BYOK is required for this model. Set up here: https://openrouter.ai/settings/integrations |
| x-ai/grok-3-mini | 2025-06-11 | $0.30 | $0.50 | 131,072 | Yes | Yes | Yes | Yes | A lightweight model that thinks before responding. Fast, smart, and great for logic-based tasks that do not require deep domain knowledge. The raw thinking traces are accessible. |
| x-ai/grok-3 | 2025-06-11 | $3.00 | $15.00 | 131,072 | Yes | Yes | No | No | Grok 3 is the latest model from xAI. It’s their flagship model that excels at enterprise use cases like data extraction, coding, and text summarization. Possesses deep domain knowledge in finance, healthcare, law, and science.
|
| mistralai/magistral-small-2506 | 2025-06-10 | $0.50 | $1.50 | 40,000 | Yes | Yes | Yes | Yes | Magistral Small is a 24B parameter instruction-tuned model based on Mistral-Small-3.1 (2503), enhanced through supervised fine-tuning on traces from Magistral Medium and further refined via reinforcement learning. It is optimized for reasoning and supports a wide multilingual range, including over 20 languages. |
| mistralai/magistral-medium-2506 | 2025-06-08 | $2.00 | $5.00 | 40,960 | Yes | Yes | Yes | Yes | Magistral is Mistral’s first reasoning model. It is ideal for general purpose use requiring longer thought processing and better accuracy than with non-reasoning LLMs. From legal research and financial forecasting to software development and creative storytelling — this model solves multi-step challenges where transparency and precision are critical. |
| mistralai/magistral-medium-2506:thinking | 2025-06-08 | $2.00 | $5.00 | 40,960 | Yes | Yes | Yes | Yes | Magistral is Mistral’s first reasoning model. It is ideal for general purpose use requiring longer thought processing and better accuracy than with non-reasoning LLMs. From legal research and financial forecasting to software development and creative storytelling — this model solves multi-step challenges where transparency and precision are critical. |
| google/gemini-2.5-pro-preview | 2025-06-05 | $1.25 | $10.00 | 1,048,576 | Yes | Yes | Yes | Yes | Gemini 2.5 Pro is Google’s state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. It employs “thinking” capabilities, enabling it to reason through responses with enhanced accuracy and nuanced context handling. Gemini 2.5 Pro achieves top-tier performance on multiple benchmarks, including first-place positioning on the LMArena leaderboard, reflecting superior human-preference alignment and complex problem-solving abilities.
|
| deepseek/deepseek-r1-0528-qwen3-8b:free | 2025-05-29 | $0.00 | $0.00 | 131,072 | No | No | Yes | Yes | DeepSeek-R1-0528 is a lightly upgraded release of DeepSeek R1 that taps more compute and smarter post-training tricks, pushing its reasoning and inference to the brink of flagship models like O3 and Gemini 2.5 Pro.
It now tops math, programming, and logic leaderboards, showcasing a step-change in depth-of-thought.
The distilled variant, DeepSeek-R1-0528-Qwen3-8B, transfers this chain-of-thought into an 8 B-parameter form, beating standard Qwen3 8B by +10 pp and tying the 235 B “thinking” giant on AIME 2024. |
| deepseek/deepseek-r1-0528-qwen3-8b | 2025-05-29 | $0.01 | $0.02 | 32,000 | No | No | Yes | Yes | DeepSeek-R1-0528 is a lightly upgraded release of DeepSeek R1 that taps more compute and smarter post-training tricks, pushing its reasoning and inference to the brink of flagship models like O3 and Gemini 2.5 Pro.
It now tops math, programming, and logic leaderboards, showcasing a step-change in depth-of-thought.
The distilled variant, DeepSeek-R1-0528-Qwen3-8B, transfers this chain-of-thought into an 8 B-parameter form, beating standard Qwen3 8B by +10 pp and tying the 235 B “thinking” giant on AIME 2024. |
| deepseek/deepseek-r1-0528:free | 2025-05-28 | $0.00 | $0.00 | 163,840 | No | No | Yes | Yes | May 28th update to the [original DeepSeek R1](/deepseek/deepseek-r1) Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It’s 671B parameters in size, with 37B active in an inference pass.
Fully open-source model. |
| deepseek/deepseek-r1-0528 | 2025-05-28 | $0.18 | $0.72 | 163,840 | Yes | Yes | Yes | Yes | May 28th update to the [original DeepSeek R1](/deepseek/deepseek-r1) Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It’s 671B parameters in size, with 37B active in an inference pass.
Fully open-source model. |
| sarvamai/sarvam-m:free | 2025-05-25 | $0.00 | $0.00 | 32,768 | No | No | No | No | Sarvam-M is a 24 B-parameter, instruction-tuned derivative of Mistral-Small-3.1-24B-Base-2503, post-trained on English plus eleven major Indic languages (bn, hi, kn, gu, mr, ml, or, pa, ta, te). The model introduces a dual-mode interface: “non-think” for low-latency chat and a optional “think” phase that exposes chain-of-thought tokens for more demanding reasoning, math, and coding tasks.
Benchmark reports show solid gains versus similarly sized open models on Indic-language QA, GSM-8K math, and SWE-Bench coding, making Sarvam-M a practical general-purpose choice for multilingual conversational agents as well as analytical workloads that mix English, native Indic scripts, or romanized text. |
| thedrummer/valkyrie-49b-v1 | 2025-05-23 | $0.65 | $1.00 | 131,072 | No | No | Yes | Yes | Built on top of NVIDIA’s Llama 3.3 Nemotron Super 49B, Valkyrie is TheDrummer’s newest model drop for creative writing. |
| anthropic/claude-opus-4 | 2025-05-22 | $15.00 | $75.00 | 200,000 | No | No | Yes | Yes | Claude Opus 4 is benchmarked as the world’s best coding model, at time of release, bringing sustained performance on complex, long-running tasks and agent workflows. It sets new benchmarks in software engineering, achieving leading results on SWE-bench (72.5%) and Terminal-bench (43.2%). Opus 4 supports extended, agentic workflows, handling thousands of task steps continuously for hours without degradation.
Read more at the [blog post here](https://www.anthropic.com/news/claude-4) |
| anthropic/claude-sonnet-4 | 2025-05-22 | $3.00 | $15.00 | 200,000 | No | No | Yes | Yes | Claude Sonnet 4 significantly enhances the capabilities of its predecessor, Sonnet 3.7, excelling in both coding and reasoning tasks with improved precision and controllability. Achieving state-of-the-art performance on SWE-bench (72.7%), Sonnet 4 balances capability and computational efficiency, making it suitable for a broad range of applications from routine coding tasks to complex software development projects. Key enhancements include improved autonomous codebase navigation, reduced error rates in agent-driven workflows, and increased reliability in following intricate instructions. Sonnet 4 is optimized for practical everyday use, providing advanced reasoning capabilities while maintaining efficiency and responsiveness in diverse internal and external scenarios.
Read more at the [blog post here](https://www.anthropic.com/news/claude-4) |
| mistralai/devstral-small-2505:free | 2025-05-21 | $0.00 | $0.00 | 32,768 | No | No | No | No | Devstral-Small-2505 is a 24B parameter agentic LLM fine-tuned from Mistral-Small-3.1, jointly developed by Mistral AI and All Hands AI for advanced software engineering tasks. It is optimized for codebase exploration, multi-file editing, and integration into coding agents, achieving state-of-the-art results on SWE-Bench Verified (46.8%).
Devstral supports a 128k context window and uses a custom Tekken tokenizer. It is text-only, with the vision encoder removed, and is suitable for local deployment on high-end consumer hardware (e.g., RTX 4090, 32GB RAM Macs). Devstral is best used in agentic workflows via the OpenHands scaffold and is compatible with inference frameworks like vLLM, Transformers, and Ollama. It is released under the Apache 2.0 license. |
| mistralai/devstral-small-2505 | 2025-05-21 | $0.02 | $0.08 | 131,072 | Yes | Yes | No | No | Devstral-Small-2505 is a 24B parameter agentic LLM fine-tuned from Mistral-Small-3.1, jointly developed by Mistral AI and All Hands AI for advanced software engineering tasks. It is optimized for codebase exploration, multi-file editing, and integration into coding agents, achieving state-of-the-art results on SWE-Bench Verified (46.8%).
Devstral supports a 128k context window and uses a custom Tekken tokenizer. It is text-only, with the vision encoder removed, and is suitable for local deployment on high-end consumer hardware (e.g., RTX 4090, 32GB RAM Macs). Devstral is best used in agentic workflows via the OpenHands scaffold and is compatible with inference frameworks like vLLM, Transformers, and Ollama. It is released under the Apache 2.0 license. |
| google/gemma-3n-e4b-it:free | 2025-05-21 | $0.00 | $0.00 | 8,192 | No | Yes | No | No | Gemma 3n E4B-it is optimized for efficient execution on mobile and low-resource devices, such as phones, laptops, and tablets. It supports multimodal inputs—including text, visual data, and audio—enabling diverse tasks such as text generation, speech recognition, translation, and image analysis. Leveraging innovations like Per-Layer Embedding (PLE) caching and the MatFormer architecture, Gemma 3n dynamically manages memory usage and computational load by selectively activating model parameters, significantly reducing runtime resource requirements.
This model supports a wide linguistic range (trained in over 140 languages) and features a flexible 32K token context window. Gemma 3n can selectively load parameters, optimizing memory and computational efficiency based on the task or device capabilities, making it well-suited for privacy-focused, offline-capable applications and on-device AI solutions. [Read more in the blog post](https://developers.googleblog.com/en/introducing-gemma-3n/) |
| google/gemma-3n-e4b-it | 2025-05-21 | $0.02 | $0.04 | 32,768 | No | No | No | No | Gemma 3n E4B-it is optimized for efficient execution on mobile and low-resource devices, such as phones, laptops, and tablets. It supports multimodal inputs—including text, visual data, and audio—enabling diverse tasks such as text generation, speech recognition, translation, and image analysis. Leveraging innovations like Per-Layer Embedding (PLE) caching and the MatFormer architecture, Gemma 3n dynamically manages memory usage and computational load by selectively activating model parameters, significantly reducing runtime resource requirements.
This model supports a wide linguistic range (trained in over 140 languages) and features a flexible 32K token context window. Gemma 3n can selectively load parameters, optimizing memory and computational efficiency based on the task or device capabilities, making it well-suited for privacy-focused, offline-capable applications and on-device AI solutions. [Read more in the blog post](https://developers.googleblog.com/en/introducing-gemma-3n/) |
| openai/codex-mini | 2025-05-16 | $1.50 | $6.00 | 200,000 | Yes | Yes | Yes | Yes | codex-mini-latest is a fine-tuned version of o4-mini specifically for use in Codex CLI. For direct use in the API, we recommend starting with gpt-4.1. |
| nousresearch/deephermes-3-mistral-24b-preview | 2025-05-10 | $0.09 | $0.37 | 32,768 | No | No | Yes | Yes | DeepHermes 3 (Mistral 24B Preview) is an instruction-tuned language model by Nous Research based on Mistral-Small-24B, designed for chat, function calling, and advanced multi-turn reasoning. It introduces a dual-mode system that toggles between intuitive chat responses and structured “deep reasoning” mode using special system prompts. Fine-tuned via distillation from R1, it supports structured output (JSON mode) and function call syntax for agent-based applications.
DeepHermes 3 supports a **reasoning toggle via system prompt**, allowing users to switch between fast, intuitive responses and deliberate, multi-step reasoning. When activated with the following specific system instruction, the model enters a *”deep thinking”* mode—generating extended chains of thought wrapped in ` |
| mistralai/mistral-medium-3 | 2025-05-07 | $0.40 | $2.00 | 131,072 | Yes | Yes | No | No | Mistral Medium 3 is a high-performance enterprise-grade language model designed to deliver frontier-level capabilities at significantly reduced operational cost. It balances state-of-the-art reasoning and multimodal performance with 8× lower cost compared to traditional large models, making it suitable for scalable deployments across professional and industrial use cases.
The model excels in domains such as coding, STEM reasoning, and enterprise adaptation. It supports hybrid, on-prem, and in-VPC deployments and is optimized for integration into custom workflows. Mistral Medium 3 offers competitive accuracy relative to larger models like Claude Sonnet 3.5/3.7, Llama 4 Maverick, and Command R+, while maintaining broad compatibility across cloud environments. |
| google/gemini-2.5-pro-preview-05-06 | 2025-05-07 | $1.25 | $10.00 | 1,048,576 | Yes | Yes | Yes | Yes | Gemini 2.5 Pro is Google’s state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. It employs “thinking” capabilities, enabling it to reason through responses with enhanced accuracy and nuanced context handling. Gemini 2.5 Pro achieves top-tier performance on multiple benchmarks, including first-place positioning on the LMArena leaderboard, reflecting superior human-preference alignment and complex problem-solving abilities. |
| arcee-ai/spotlight | 2025-05-06 | $0.18 | $0.18 | 131,072 | No | No | No | No | Spotlight is a 7‑billion‑parameter vision‑language model derived from Qwen 2.5‑VL and fine‑tuned by Arcee AI for tight image‑text grounding tasks. It offers a 32 k‑token context window, enabling rich multimodal conversations that combine lengthy documents with one or more images. Training emphasized fast inference on consumer GPUs while retaining strong captioning, visual‐question‑answering, and diagram‑analysis accuracy. As a result, Spotlight slots neatly into agent workflows where screenshots, charts or UI mock‑ups need to be interpreted on the fly. Early benchmarks show it matching or out‑scoring larger VLMs such as LLaVA‑1.6 13 B on popular VQA and POPE alignment tests. |
| arcee-ai/maestro-reasoning | 2025-05-06 | $0.90 | $3.30 | 131,072 | No | No | No | No | Maestro Reasoning is Arcee’s flagship analysis model: a 32 B‑parameter derivative of Qwen 2.5‑32 B tuned with DPO and chain‑of‑thought RL for step‑by‑step logic. Compared to the earlier 7 B preview, the production 32 B release widens the context window to 128 k tokens and doubles pass‑rate on MATH and GSM‑8K, while also lifting code completion accuracy. Its instruction style encourages structured “thought → answer” traces that can be parsed or hidden according to user preference. That transparency pairs well with audit‑focused industries like finance or healthcare where seeing the reasoning path matters. In Arcee Conductor, Maestro is automatically selected for complex, multi‑constraint queries that smaller SLMs bounce. |
| arcee-ai/virtuoso-large | 2025-05-06 | $0.75 | $1.20 | 131,072 | No | No | No | No | Virtuoso‑Large is Arcee’s top‑tier general‑purpose LLM at 72 B parameters, tuned to tackle cross‑domain reasoning, creative writing and enterprise QA. Unlike many 70 B peers, it retains the 128 k context inherited from Qwen 2.5, letting it ingest books, codebases or financial filings wholesale. Training blended DeepSeek R1 distillation, multi‑epoch supervised fine‑tuning and a final DPO/RLHF alignment stage, yielding strong performance on BIG‑Bench‑Hard, GSM‑8K and long‑context Needle‑In‑Haystack tests. Enterprises use Virtuoso‑Large as the “fallback” brain in Conductor pipelines when other SLMs flag low confidence. Despite its size, aggressive KV‑cache optimizations keep first‑token latency in the low‑second range on 8× H100 nodes, making it a practical production‑grade powerhouse. |
| arcee-ai/coder-large | 2025-05-06 | $0.50 | $0.80 | 32,768 | No | No | No | No | Coder‑Large is a 32 B‑parameter offspring of Qwen 2.5‑Instruct that has been further trained on permissively‑licensed GitHub, CodeSearchNet and synthetic bug‑fix corpora. It supports a 32k context window, enabling multi‑file refactoring or long diff review in a single call, and understands 30‑plus programming languages with special attention to TypeScript, Go and Terraform. Internal benchmarks show 5–8 pt gains over CodeLlama‑34 B‑Python on HumanEval and competitive BugFix scores thanks to a reinforcement pass that rewards compilable output. The model emits structured explanations alongside code blocks by default, making it suitable for educational tooling as well as production copilot scenarios. Cost‑wise, Together AI prices it well below proprietary incumbents, so teams can scale interactive coding without runaway spend. |
| microsoft/phi-4-reasoning-plus | 2025-05-02 | $0.07 | $0.35 | 32,768 | No | Yes | Yes | Yes | Phi-4-reasoning-plus is an enhanced 14B parameter model from Microsoft, fine-tuned from Phi-4 with additional reinforcement learning to boost accuracy on math, science, and code reasoning tasks. It uses the same dense decoder-only transformer architecture as Phi-4, but generates longer, more comprehensive outputs structured into a step-by-step reasoning trace and final answer.
While it offers improved benchmark scores over Phi-4-reasoning across tasks like AIME, OmniMath, and HumanEvalPlus, its responses are typically ~50% longer, resulting in higher latency. Designed for English-only applications, it is well-suited for structured reasoning workflows where output quality takes priority over response speed. |
| inception/mercury-coder | 2025-04-30 | $0.25 | $1.00 | 128,000 | Yes | Yes | No | No | Mercury Coder is the first diffusion large language model (dLLM). Applying a breakthrough discrete diffusion approach, the model runs 5-10x faster than even speed optimized models like Claude 3.5 Haiku and GPT-4o Mini while matching their performance. Mercury Coder’s speed means that developers can stay in the flow while coding, enjoying rapid chat-based iteration and responsive code completion suggestions. On Copilot Arena, Mercury Coder ranks 1st in speed and ties for 2nd in quality. Read more in the [blog post here](https://www.inceptionlabs.ai/introducing-mercury). |
| qwen/qwen3-4b:free | 2025-04-30 | $0.00 | $0.00 | 40,960 | Yes | Yes | Yes | Yes | Qwen3-4B is a 4 billion parameter dense language model from the Qwen3 series, designed to support both general-purpose and reasoning-intensive tasks. It introduces a dual-mode architecture—thinking and non-thinking—allowing dynamic switching between high-precision logical reasoning and efficient dialogue generation. This makes it well-suited for multi-turn chat, instruction following, and complex agent workflows. |
| opengvlab/internvl3-14b | 2025-04-30 | $0.20 | $0.40 | 12,288 | No | No | No | No | The 14b version of the InternVL3 series. An advanced multimodal large language model (MLLM) series that demonstrates superior overall performance. Compared to InternVL 2.5, InternVL3 exhibits superior multimodal perception and reasoning capabilities, while further extending its multimodal capabilities to encompass tool usage, GUI agents, industrial image analysis, 3D vision perception, and more. |
| deepseek/deepseek-prover-v2 | 2025-04-30 | $0.50 | $2.18 | 163,840 | No | Yes | No | No | DeepSeek Prover V2 is a 671B parameter model, speculated to be geared towards logic and mathematics. Likely an upgrade from [DeepSeek-Prover-V1.5](https://huggingface.co/deepseek-ai/DeepSeek-Prover-V1.5-RL) Not much is known about the model yet, as DeepSeek released it on Hugging Face without an announcement or description. |
| meta-llama/llama-guard-4-12b | 2025-04-30 | $0.18 | $0.18 | 163,840 | No | Yes | No | No | Llama Guard 4 is a Llama 4 Scout-derived multimodal pretrained model, fine-tuned for content safety classification. Similar to previous versions, it can be used to classify content in both LLM inputs (prompt classification) and in LLM responses (response classification). It acts as an LLM—generating text in its output that indicates whether a given prompt or response is safe or unsafe, and if unsafe, it also lists the content categories violated.
Llama Guard 4 was aligned to safeguard against the standardized MLCommons hazards taxonomy and designed to support multimodal Llama 4 capabilities. Specifically, it combines features from previous Llama Guard models, providing content moderation for English and multiple supported languages, along with enhanced capabilities to handle mixed text-and-image prompts, including multiple images. Additionally, Llama Guard 4 is integrated into the Llama Moderations API, extending robust safety classification to text and images. |
| qwen/qwen3-30b-a3b:free | 2025-04-29 | $0.00 | $0.00 | 40,960 | No | No | Yes | Yes | Qwen3, the latest generation in the Qwen large language model series, features both dense and mixture-of-experts (MoE) architectures to excel in reasoning, multilingual support, and advanced agent tasks. Its unique ability to switch seamlessly between a thinking mode for complex reasoning and a non-thinking mode for efficient dialogue ensures versatile, high-quality performance.
Significantly outperforming prior models like QwQ and Qwen2.5, Qwen3 delivers superior mathematics, coding, commonsense reasoning, creative writing, and interactive dialogue capabilities. The Qwen3-30B-A3B variant includes 30.5 billion parameters (3.3 billion activated), 48 layers, 128 experts (8 activated per task), and supports up to 131K token contexts with YaRN, setting a new standard among open-source models. |
| qwen/qwen3-30b-a3b | 2025-04-29 | $0.02 | $0.08 | 40,960 | Yes | Yes | Yes | Yes | Qwen3, the latest generation in the Qwen large language model series, features both dense and mixture-of-experts (MoE) architectures to excel in reasoning, multilingual support, and advanced agent tasks. Its unique ability to switch seamlessly between a thinking mode for complex reasoning and a non-thinking mode for efficient dialogue ensures versatile, high-quality performance.
Significantly outperforming prior models like QwQ and Qwen2.5, Qwen3 delivers superior mathematics, coding, commonsense reasoning, creative writing, and interactive dialogue capabilities. The Qwen3-30B-A3B variant includes 30.5 billion parameters (3.3 billion activated), 48 layers, 128 experts (8 activated per task), and supports up to 131K token contexts with YaRN, setting a new standard among open-source models. |
| qwen/qwen3-8b:free | 2025-04-29 | $0.00 | $0.00 | 40,960 | No | No | Yes | Yes | Qwen3-8B is a dense 8.2B parameter causal language model from the Qwen3 series, designed for both reasoning-heavy tasks and efficient dialogue. It supports seamless switching between “thinking” mode for math, coding, and logical inference, and “non-thinking” mode for general conversation. The model is fine-tuned for instruction-following, agent integration, creative writing, and multilingual use across 100+ languages and dialects. It natively supports a 32K token context window and can extend to 131K tokens with YaRN scaling. |
| qwen/qwen3-8b | 2025-04-29 | $0.04 | $0.14 | 128,000 | No | No | Yes | Yes | Qwen3-8B is a dense 8.2B parameter causal language model from the Qwen3 series, designed for both reasoning-heavy tasks and efficient dialogue. It supports seamless switching between “thinking” mode for math, coding, and logical inference, and “non-thinking” mode for general conversation. The model is fine-tuned for instruction-following, agent integration, creative writing, and multilingual use across 100+ languages and dialects. It natively supports a 32K token context window and can extend to 131K tokens with YaRN scaling. |
| qwen/qwen3-14b:free | 2025-04-29 | $0.00 | $0.00 | 40,960 | No | No | Yes | Yes | Qwen3-14B is a dense 14.8B parameter causal language model from the Qwen3 series, designed for both complex reasoning and efficient dialogue. It supports seamless switching between a “thinking” mode for tasks like math, programming, and logical inference, and a “non-thinking” mode for general-purpose conversation. The model is fine-tuned for instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. |
| qwen/qwen3-14b | 2025-04-29 | $0.06 | $0.24 | 40,960 | Yes | Yes | Yes | Yes | Qwen3-14B is a dense 14.8B parameter causal language model from the Qwen3 series, designed for both complex reasoning and efficient dialogue. It supports seamless switching between a “thinking” mode for tasks like math, programming, and logical inference, and a “non-thinking” mode for general-purpose conversation. The model is fine-tuned for instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. |
| qwen/qwen3-32b | 2025-04-29 | $0.02 | $0.07 | 40,960 | Yes | Yes | Yes | Yes | Qwen3-32B is a dense 32.8B parameter causal language model from the Qwen3 series, optimized for both complex reasoning and efficient dialogue. It supports seamless switching between a “thinking” mode for tasks like math, coding, and logical inference, and a “non-thinking” mode for faster, general-purpose conversation. The model demonstrates strong performance in instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. |
| qwen/qwen3-235b-a22b:free | 2025-04-29 | $0.00 | $0.00 | 131,072 | Yes | Yes | Yes | Yes | Qwen3-235B-A22B is a 235B parameter mixture-of-experts (MoE) model developed by Qwen, activating 22B parameters per forward pass. It supports seamless switching between a “thinking” mode for complex reasoning, math, and code tasks, and a “non-thinking” mode for general conversational efficiency. The model demonstrates strong reasoning ability, multilingual support (100+ languages and dialects), advanced instruction-following, and agent tool-calling capabilities. It natively handles a 32K token context window and extends up to 131K tokens using YaRN-based scaling. |
| qwen/qwen3-235b-a22b | 2025-04-29 | $0.13 | $0.60 | 40,960 | Yes | Yes | Yes | Yes | Qwen3-235B-A22B is a 235B parameter mixture-of-experts (MoE) model developed by Qwen, activating 22B parameters per forward pass. It supports seamless switching between a “thinking” mode for complex reasoning, math, and code tasks, and a “non-thinking” mode for general conversational efficiency. The model demonstrates strong reasoning ability, multilingual support (100+ languages and dialects), advanced instruction-following, and agent tool-calling capabilities. It natively handles a 32K token context window and extends up to 131K tokens using YaRN-based scaling. |
| tngtech/deepseek-r1t-chimera:free | 2025-04-27 | $0.00 | $0.00 | 163,840 | No | No | Yes | Yes | DeepSeek-R1T-Chimera is created by merging DeepSeek-R1 and DeepSeek-V3 (0324), combining the reasoning capabilities of R1 with the token efficiency improvements of V3. It is based on a DeepSeek-MoE Transformer architecture and is optimized for general text generation tasks.
The model merges pretrained weights from both source models to balance performance across reasoning, efficiency, and instruction-following tasks. It is released under the MIT license and intended for research and commercial use. |
| tngtech/deepseek-r1t-chimera | 2025-04-27 | $0.18 | $0.72 | 163,840 | No | No | Yes | Yes | DeepSeek-R1T-Chimera is created by merging DeepSeek-R1 and DeepSeek-V3 (0324), combining the reasoning capabilities of R1 with the token efficiency improvements of V3. It is based on a DeepSeek-MoE Transformer architecture and is optimized for general text generation tasks.
The model merges pretrained weights from both source models to balance performance across reasoning, efficiency, and instruction-following tasks. It is released under the MIT license and intended for research and commercial use. |
| microsoft/mai-ds-r1:free | 2025-04-21 | $0.00 | $0.00 | 163,840 | No | No | Yes | Yes | MAI-DS-R1 is a post-trained variant of DeepSeek-R1 developed by the Microsoft AI team to improve the model’s responsiveness on previously blocked topics while enhancing its safety profile. Built on top of DeepSeek-R1’s reasoning foundation, it integrates 110k examples from the Tulu-3 SFT dataset and 350k internally curated multilingual safety-alignment samples. The model retains strong reasoning, coding, and problem-solving capabilities, while unblocking a wide range of prompts previously restricted in R1.
MAI-DS-R1 demonstrates improved performance on harm mitigation benchmarks and maintains competitive results across general reasoning tasks. It surpasses R1-1776 in satisfaction metrics for blocked queries and reduces leakage in harmful content categories. The model is based on a transformer MoE architecture and is suitable for general-purpose use cases, excluding high-stakes domains such as legal, medical, or autonomous systems. |
| microsoft/mai-ds-r1 | 2025-04-21 | $0.20 | $0.80 | 163,840 | No | No | Yes | Yes | MAI-DS-R1 is a post-trained variant of DeepSeek-R1 developed by the Microsoft AI team to improve the model’s responsiveness on previously blocked topics while enhancing its safety profile. Built on top of DeepSeek-R1’s reasoning foundation, it integrates 110k examples from the Tulu-3 SFT dataset and 350k internally curated multilingual safety-alignment samples. The model retains strong reasoning, coding, and problem-solving capabilities, while unblocking a wide range of prompts previously restricted in R1.
MAI-DS-R1 demonstrates improved performance on harm mitigation benchmarks and maintains competitive results across general reasoning tasks. It surpasses R1-1776 in satisfaction metrics for blocked queries and reduces leakage in harmful content categories. The model is based on a transformer MoE architecture and is suitable for general-purpose use cases, excluding high-stakes domains such as legal, medical, or autonomous systems. |
| thudm/glm-z1-32b | 2025-04-18 | $0.02 | $0.08 | 32,768 | No | No | Yes | Yes | GLM-Z1-32B-0414 is an enhanced reasoning variant of GLM-4-32B, built for deep mathematical, logical, and code-oriented problem solving. It applies extended reinforcement learning—both task-specific and general pairwise preference-based—to improve performance on complex multi-step tasks. Compared to the base GLM-4-32B model, Z1 significantly boosts capabilities in structured reasoning and formal domains.
The model supports enforced “thinking” steps via prompt engineering and offers improved coherence for long-form outputs. It’s optimized for use in agentic workflows, and includes support for long context (via YaRN), JSON tool calling, and fine-grained sampling configuration for stable inference. Ideal for use cases requiring deliberate, multi-step reasoning or formal derivations. |
| thudm/glm-4-32b | 2025-04-18 | $0.24 | $0.24 | 32,000 | No | No | No | No | GLM-4-32B-0414 is a 32B bilingual (Chinese-English) open-weight language model optimized for code generation, function calling, and agent-style tasks. Pretrained on 15T of high-quality and reasoning-heavy data, it was further refined using human preference alignment, rejection sampling, and reinforcement learning. The model excels in complex reasoning, artifact generation, and structured output tasks, achieving performance comparable to GPT-4o and DeepSeek-V3-0324 across several benchmarks. |
| openai/o4-mini-high | 2025-04-16 | $1.10 | $4.40 | 200,000 | Yes | Yes | Yes | Yes | OpenAI o4-mini-high is the same model as [o4-mini](/openai/o4-mini) with reasoning_effort set to high.
OpenAI o4-mini is a compact reasoning model in the o-series, optimized for fast, cost-efficient performance while retaining strong multimodal and agentic capabilities. It supports tool use and demonstrates competitive reasoning and coding performance across benchmarks like AIME (99.5% with Python) and SWE-bench, outperforming its predecessor o3-mini and even approaching o3 in some domains.
Despite its smaller size, o4-mini exhibits high accuracy in STEM tasks, visual problem solving (e.g., MathVista, MMMU), and code editing. It is especially well-suited for high-throughput scenarios where latency or cost is critical. Thanks to its efficient architecture and refined reinforcement learning training, o4-mini can chain tools, generate structured outputs, and solve multi-step tasks with minimal delay—often in under a minute. |
| openai/o3 | 2025-04-16 | $2.00 | $8.00 | 200,000 | Yes | Yes | Yes | Yes | o3 is a well-rounded and powerful model across domains. It sets a new standard for math, science, coding, and visual reasoning tasks. It also excels at technical writing and instruction-following. Use it to think through multi-step problems that involve analysis across text, code, and images. Note that BYOK is required for this model. Set up here: https://openrouter.ai/settings/integrations |
| openai/o4-mini | 2025-04-16 | $1.10 | $4.40 | 200,000 | Yes | Yes | Yes | Yes | OpenAI o4-mini is a compact reasoning model in the o-series, optimized for fast, cost-efficient performance while retaining strong multimodal and agentic capabilities. It supports tool use and demonstrates competitive reasoning and coding performance across benchmarks like AIME (99.5% with Python) and SWE-bench, outperforming its predecessor o3-mini and even approaching o3 in some domains.
Despite its smaller size, o4-mini exhibits high accuracy in STEM tasks, visual problem solving (e.g., MathVista, MMMU), and code editing. It is especially well-suited for high-throughput scenarios where latency or cost is critical. Thanks to its efficient architecture and refined reinforcement learning training, o4-mini can chain tools, generate structured outputs, and solve multi-step tasks with minimal delay—often in under a minute. |
| shisa-ai/shisa-v2-llama3.3-70b:free | 2025-04-16 | $0.00 | $0.00 | 32,768 | No | No | No | No | Shisa V2 Llama 3.3 70B is a bilingual Japanese-English chat model fine-tuned by Shisa.AI on Meta’s Llama-3.3-70B-Instruct base. It prioritizes Japanese language performance while retaining strong English capabilities. The model was optimized entirely through post-training, using a refined mix of supervised fine-tuning (SFT) and DPO datasets including regenerated ShareGPT-style data, translation tasks, roleplaying conversations, and instruction-following prompts. Unlike earlier Shisa releases, this version avoids tokenizer modifications or extended pretraining.
Shisa V2 70B achieves leading Japanese task performance across a wide range of custom and public benchmarks, including JA MT Bench, ELYZA 100, and Rakuda. It supports a 128K token context length and integrates smoothly with inference frameworks like vLLM and SGLang. While it inherits safety characteristics from its base model, no additional alignment was applied. The model is intended for high-performance bilingual chat, instruction following, and translation tasks across JA/EN. |
| shisa-ai/shisa-v2-llama3.3-70b | 2025-04-16 | $0.02 | $0.08 | 32,768 | No | No | No | No | Shisa V2 Llama 3.3 70B is a bilingual Japanese-English chat model fine-tuned by Shisa.AI on Meta’s Llama-3.3-70B-Instruct base. It prioritizes Japanese language performance while retaining strong English capabilities. The model was optimized entirely through post-training, using a refined mix of supervised fine-tuning (SFT) and DPO datasets including regenerated ShareGPT-style data, translation tasks, roleplaying conversations, and instruction-following prompts. Unlike earlier Shisa releases, this version avoids tokenizer modifications or extended pretraining.
Shisa V2 70B achieves leading Japanese task performance across a wide range of custom and public benchmarks, including JA MT Bench, ELYZA 100, and Rakuda. It supports a 128K token context length and integrates smoothly with inference frameworks like vLLM and SGLang. While it inherits safety characteristics from its base model, no additional alignment was applied. The model is intended for high-performance bilingual chat, instruction following, and translation tasks across JA/EN. |
| openai/gpt-4.1 | 2025-04-14 | $2.00 | $8.00 | 1,047,576 | Yes | Yes | No | No | GPT-4.1 is a flagship large language model optimized for advanced instruction following, real-world software engineering, and long-context reasoning. It supports a 1 million token context window and outperforms GPT-4o and GPT-4.5 across coding (54.6% SWE-bench Verified), instruction compliance (87.4% IFEval), and multimodal understanding benchmarks. It is tuned for precise code diffs, agent reliability, and high recall in large document contexts, making it ideal for agents, IDE tooling, and enterprise knowledge retrieval. |
| openai/gpt-4.1-mini | 2025-04-14 | $0.40 | $1.60 | 1,047,576 | Yes | Yes | No | No | GPT-4.1 Mini is a mid-sized model delivering performance competitive with GPT-4o at substantially lower latency and cost. It retains a 1 million token context window and scores 45.1% on hard instruction evals, 35.8% on MultiChallenge, and 84.1% on IFEval. Mini also shows strong coding ability (e.g., 31.6% on Aider’s polyglot diff benchmark) and vision understanding, making it suitable for interactive applications with tight performance constraints. |
| openai/gpt-4.1-nano | 2025-04-14 | $0.10 | $0.40 | 1,047,576 | Yes | Yes | No | No | For tasks that demand low latency, GPT‑4.1 nano is the fastest and cheapest model in the GPT-4.1 series. It delivers exceptional performance at a small size with its 1 million token context window, and scores 80.1% on MMLU, 50.3% on GPQA, and 9.8% on Aider polyglot coding – even higher than GPT‑4o mini. It’s ideal for tasks like classification or autocompletion. |
| eleutherai/llemma_7b | 2025-04-14 | $0.80 | $1.20 | 4,096 | No | No | No | No | Llemma 7B is a language model for mathematics. It was initialized with Code Llama 7B weights, and trained on the Proof-Pile-2 for 200B tokens. Llemma models are particularly strong at chain-of-thought mathematical reasoning and using computational tools for mathematics, such as Python and formal theorem provers. |
| alfredpros/codellama-7b-instruct-solidity | 2025-04-14 | $0.70 | $1.10 | 8,192 | No | No | No | No | A finetuned 7 billion parameters Code LLaMA – Instruct model to generate Solidity smart contract using 4-bit QLoRA finetuning provided by PEFT library. |
| arliai/qwq-32b-arliai-rpr-v1:free | 2025-04-13 | $0.00 | $0.00 | 32,768 | No | No | Yes | Yes | QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself.
The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity. |
| arliai/qwq-32b-arliai-rpr-v1 | 2025-04-13 | $0.01 | $0.04 | 32,768 | No | No | Yes | Yes | QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself.
The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity. |
| agentica-org/deepcoder-14b-preview:free | 2025-04-13 | $0.00 | $0.00 | 96,000 | No | No | Yes | Yes | DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini |
| agentica-org/deepcoder-14b-preview | 2025-04-13 | $0.01 | $0.01 | 96,000 | No | No | Yes | Yes | DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini |
| moonshotai/kimi-vl-a3b-thinking:free | 2025-04-10 | $0.00 | $0.00 | 131,072 | No | No | Yes | Yes | Kimi-VL is a lightweight Mixture-of-Experts vision-language model that activates only 2.8B parameters per step while delivering strong performance on multimodal reasoning and long-context tasks. The Kimi-VL-A3B-Thinking variant, fine-tuned with chain-of-thought and reinforcement learning, excels in math and visual reasoning benchmarks like MathVision, MMMU, and MathVista, rivaling much larger models such as Qwen2.5-VL-7B and Gemma-3-12B. It supports 128K context and high-resolution input via its MoonViT encoder. |
| moonshotai/kimi-vl-a3b-thinking | 2025-04-10 | $0.02 | $0.10 | 131,072 | No | No | Yes | Yes | Kimi-VL is a lightweight Mixture-of-Experts vision-language model that activates only 2.8B parameters per step while delivering strong performance on multimodal reasoning and long-context tasks. The Kimi-VL-A3B-Thinking variant, fine-tuned with chain-of-thought and reinforcement learning, excels in math and visual reasoning benchmarks like MathVision, MMMU, and MathVista, rivaling much larger models such as Qwen2.5-VL-7B and Gemma-3-12B. It supports 128K context and high-resolution input via its MoonViT encoder. |
| x-ai/grok-3-mini-beta | 2025-04-10 | $0.30 | $0.50 | 131,072 | No | Yes | Yes | Yes | Grok 3 Mini is a lightweight, smaller thinking model. Unlike traditional models that generate answers immediately, Grok 3 Mini thinks before responding. It’s ideal for reasoning-heavy tasks that don’t demand extensive domain knowledge, and shines in math-specific and quantitative use cases, such as solving challenging puzzles or math problems.
Transparent “thinking” traces accessible. Defaults to low reasoning, can boost with setting `reasoning: { effort: “high” }`
Note: That there are two xAI endpoints for this model. By default when using this model we will always route you to the base endpoint. If you want the fast endpoint you can add `provider: { sort: throughput}`, to sort by throughput instead.
|
| x-ai/grok-3-beta | 2025-04-10 | $3.00 | $15.00 | 131,072 | No | Yes | No | No | Grok 3 is the latest model from xAI. It’s their flagship model that excels at enterprise use cases like data extraction, coding, and text summarization. Possesses deep domain knowledge in finance, healthcare, law, and science.
Excels in structured tasks and benchmarks like GPQA, LCB, and MMLU-Pro where it outperforms Grok 3 Mini even on high thinking.
Note: That there are two xAI endpoints for this model. By default when using this model we will always route you to the base endpoint. If you want the fast endpoint you can add `provider: { sort: throughput}`, to sort by throughput instead.
|
| nvidia/llama-3.3-nemotron-super-49b-v1 | 2025-04-08 | $0.13 | $0.40 | 131,072 | No | No | No | No | Llama-3.3-Nemotron-Super-49B-v1 is a large language model (LLM) optimized for advanced reasoning, conversational interactions, retrieval-augmented generation (RAG), and tool-calling tasks. Derived from Meta’s Llama-3.3-70B-Instruct, it employs a Neural Architecture Search (NAS) approach, significantly enhancing efficiency and reducing memory requirements. This allows the model to support a context length of up to 128K tokens and fit efficiently on single high-performance GPUs, such as NVIDIA H200.
Note: you must include `detailed thinking on` in the system prompt to enable reasoning. Please see [Usage Recommendations](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1#quick-start-and-usage-recommendations) for more. |
| nvidia/llama-3.1-nemotron-ultra-253b-v1:free | 2025-04-08 | $0.00 | $0.00 | 131,072 | No | No | No | No | Llama-3.1-Nemotron-Ultra-253B-v1 is a large language model (LLM) optimized for advanced reasoning, human-interactive chat, retrieval-augmented generation (RAG), and tool-calling tasks. Derived from Meta’s Llama-3.1-405B-Instruct, it has been significantly customized using Neural Architecture Search (NAS), resulting in enhanced efficiency, reduced memory usage, and improved inference latency. The model supports a context length of up to 128K tokens and can operate efficiently on an 8x NVIDIA H100 node.
Note: you must include `detailed thinking on` in the system prompt to enable reasoning. Please see [Usage Recommendations](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1#quick-start-and-usage-recommendations) for more. |
| nvidia/llama-3.1-nemotron-ultra-253b-v1 | 2025-04-08 | $0.60 | $1.80 | 131,072 | No | No | Yes | Yes | Llama-3.1-Nemotron-Ultra-253B-v1 is a large language model (LLM) optimized for advanced reasoning, human-interactive chat, retrieval-augmented generation (RAG), and tool-calling tasks. Derived from Meta’s Llama-3.1-405B-Instruct, it has been significantly customized using Neural Architecture Search (NAS), resulting in enhanced efficiency, reduced memory usage, and improved inference latency. The model supports a context length of up to 128K tokens and can operate efficiently on an 8x NVIDIA H100 node.
Note: you must include `detailed thinking on` in the system prompt to enable reasoning. Please see [Usage Recommendations](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1#quick-start-and-usage-recommendations) for more. |
| meta-llama/llama-4-maverick | 2025-04-06 | $0.15 | $0.60 | 1,048,576 | Yes | Yes | No | No | Llama 4 Maverick 17B Instruct (128E) is a high-capacity multimodal language model from Meta, built on a mixture-of-experts (MoE) architecture with 128 experts and 17 billion active parameters per forward pass (400B total). It supports multilingual text and image input, and produces multilingual text and code output across 12 supported languages. Optimized for vision-language tasks, Maverick is instruction-tuned for assistant-like behavior, image reasoning, and general-purpose multimodal interaction.
Maverick features early fusion for native multimodality and a 1 million token context window. It was trained on a curated mixture of public, licensed, and Meta-platform data, covering ~22 trillion tokens, with a knowledge cutoff in August 2024. Released on April 5, 2025 under the Llama 4 Community License, Maverick is suited for research and commercial applications requiring advanced multimodal understanding and high model throughput. |
| meta-llama/llama-4-scout | 2025-04-06 | $0.08 | $0.30 | 1,048,576 | Yes | Yes | No | No | Llama 4 Scout 17B Instruct (16E) is a mixture-of-experts (MoE) language model developed by Meta, activating 17 billion parameters out of a total of 109B. It supports native multimodal input (text and image) and multilingual output (text and code) across 12 supported languages. Designed for assistant-style interaction and visual reasoning, Scout uses 16 experts per forward pass and features a context length of 10 million tokens, with a training corpus of ~40 trillion tokens.
Built for high efficiency and local or commercial deployment, Llama 4 Scout incorporates early fusion for seamless modality integration. It is instruction-tuned for use in multilingual chat, captioning, and image understanding tasks. Released under the Llama 4 Community License, it was last trained on data up to August 2024 and launched publicly on April 5, 2025. |
| deepseek/deepseek-v3-base | 2025-03-29 | $0.20 | $0.80 | 163,840 | No | No | No | No | Note that this is a base model mostly meant for testing, you need to provide detailed prompts for the model to return useful responses.
DeepSeek-V3 Base is a 671B parameter open Mixture-of-Experts (MoE) language model with 37B active parameters per forward pass and a context length of 128K tokens. Trained on 14.8T tokens using FP8 mixed precision, it achieves high training efficiency and stability, with strong performance across language, reasoning, math, and coding tasks.
DeepSeek-V3 Base is the pre-trained model behind [DeepSeek V3](/deepseek/deepseek-chat-v3) |
| scb10x/llama3.1-typhoon2-70b-instruct | 2025-03-29 | $0.88 | $0.88 | 8,192 | No | No | No | No | Llama3.1-Typhoon2-70B-Instruct is a Thai-English instruction-tuned language model with 70 billion parameters, built on Llama 3.1. It demonstrates strong performance across general instruction-following, math, coding, and tool-use tasks, with state-of-the-art results in Thai-specific benchmarks such as IFEval, MT-Bench, and Thai-English code-switching.
The model excels in bilingual reasoning and function-calling scenarios, offering high accuracy across diverse domains. Comparative evaluations show consistent improvements over prior Thai LLMs and other Llama-based baselines. Full results and methodology are available in the [technical report.](https://arxiv.org/abs/2412.13702) |
| google/gemini-2.5-pro-exp-03-25 | 2025-03-25 | $0.00 | $0.00 | 1,048,576 | Yes | Yes | No | No | This model has been deprecated by Google in favor of the (paid Preview model)[google/gemini-2.5-pro-preview]
Gemini 2.5 Pro is Google’s state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. It employs “thinking” capabilities, enabling it to reason through responses with enhanced accuracy and nuanced context handling. Gemini 2.5 Pro achieves top-tier performance on multiple benchmarks, including first-place positioning on the LMArena leaderboard, reflecting superior human-preference alignment and complex problem-solving abilities. |
| qwen/qwen2.5-vl-32b-instruct:free | 2025-03-24 | $0.00 | $0.00 | 8,192 | No | Yes | No | No | Qwen2.5-VL-32B is a multimodal vision-language model fine-tuned through reinforcement learning for enhanced mathematical reasoning, structured outputs, and visual problem-solving capabilities. It excels at visual analysis tasks, including object recognition, textual interpretation within images, and precise event localization in extended videos. Qwen2.5-VL-32B demonstrates state-of-the-art performance across multimodal benchmarks such as MMMU, MathVista, and VideoMME, while maintaining strong reasoning and clarity in text-based tasks like MMLU, mathematical problem-solving, and code generation. |
| qwen/qwen2.5-vl-32b-instruct | 2025-03-24 | $0.02 | $0.08 | 16,384 | Yes | Yes | No | No | Qwen2.5-VL-32B is a multimodal vision-language model fine-tuned through reinforcement learning for enhanced mathematical reasoning, structured outputs, and visual problem-solving capabilities. It excels at visual analysis tasks, including object recognition, textual interpretation within images, and precise event localization in extended videos. Qwen2.5-VL-32B demonstrates state-of-the-art performance across multimodal benchmarks such as MMMU, MathVista, and VideoMME, while maintaining strong reasoning and clarity in text-based tasks like MMLU, mathematical problem-solving, and code generation. |
| deepseek/deepseek-chat-v3-0324:free | 2025-03-24 | $0.00 | $0.00 | 163,840 | No | No | No | No | DeepSeek V3, a 685B-parameter, mixture-of-experts model, is the latest iteration of the flagship chat model family from the DeepSeek team.
It succeeds the [DeepSeek V3](/deepseek/deepseek-chat-v3) model and performs really well on a variety of tasks. |
| deepseek/deepseek-chat-v3-0324 | 2025-03-24 | $0.18 | $0.72 | 163,840 | Yes | Yes | No | No | DeepSeek V3, a 685B-parameter, mixture-of-experts model, is the latest iteration of the flagship chat model family from the DeepSeek team.
It succeeds the [DeepSeek V3](/deepseek/deepseek-chat-v3) model and performs really well on a variety of tasks. |
| featherless/qwerky-72b:free | 2025-03-20 | $0.00 | $0.00 | 32,768 | No | No | No | No | Qrwkv-72B is a linear-attention RWKV variant of the Qwen 2.5 72B model, optimized to significantly reduce computational cost at scale. Leveraging linear attention, it achieves substantial inference speedups (>1000x) while retaining competitive accuracy on common benchmarks like ARC, HellaSwag, Lambada, and MMLU. It inherits knowledge and language support from Qwen 2.5, supporting approximately 30 languages, making it suitable for efficient inference in large-context applications. |
| openai/o1-pro | 2025-03-20 | $150.00 | $600.00 | 200,000 | Yes | Yes | Yes | Yes | The o1 series of models are trained with reinforcement learning to think before they answer and perform complex reasoning. The o1-pro model uses more compute to think harder and provide consistently better answers. |
| mistralai/mistral-small-3.1-24b-instruct:free | 2025-03-18 | $0.00 | $0.00 | 128,000 | Yes | Yes | No | No | Mistral Small 3.1 24B Instruct is an upgraded variant of Mistral Small 3 (2501), featuring 24 billion parameters with advanced multimodal capabilities. It provides state-of-the-art performance in text-based reasoning and vision tasks, including image analysis, programming, mathematical reasoning, and multilingual support across dozens of languages. Equipped with an extensive 128k token context window and optimized for efficient local inference, it supports use cases such as conversational agents, function calling, long-document comprehension, and privacy-sensitive deployments. The updated version is [Mistral Small 3.2](mistralai/mistral-small-3.2-24b-instruct) |
| mistralai/mistral-small-3.1-24b-instruct | 2025-03-18 | $0.02 | $0.07 | 131,072 | Yes | Yes | No | No | Mistral Small 3.1 24B Instruct is an upgraded variant of Mistral Small 3 (2501), featuring 24 billion parameters with advanced multimodal capabilities. It provides state-of-the-art performance in text-based reasoning and vision tasks, including image analysis, programming, mathematical reasoning, and multilingual support across dozens of languages. Equipped with an extensive 128k token context window and optimized for efficient local inference, it supports use cases such as conversational agents, function calling, long-document comprehension, and privacy-sensitive deployments. The updated version is [Mistral Small 3.2](mistralai/mistral-small-3.2-24b-instruct) |
| google/gemma-3-4b-it:free | 2025-03-14 | $0.00 | $0.00 | 32,768 | Yes | Yes | No | No | Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. |
| google/gemma-3-4b-it | 2025-03-14 | $0.02 | $0.04 | 131,072 | No | Yes | No | No | Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. |
| google/gemma-3-12b-it:free | 2025-03-14 | $0.00 | $0.00 | 96,000 | Yes | Yes | No | No | Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 12B is the second largest in the family of Gemma 3 models after [Gemma 3 27B](google/gemma-3-27b-it) |
| google/gemma-3-12b-it | 2025-03-14 | $0.05 | $0.19 | 96,000 | No | Yes | No | No | Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 12B is the second largest in the family of Gemma 3 models after [Gemma 3 27B](google/gemma-3-27b-it) |
| cohere/command-a | 2025-03-14 | $2.00 | $8.00 | 32,768 | Yes | Yes | No | No | Command A is an open-weights 111B parameter model with a 256k context window focused on delivering great performance across agentic, multilingual, and coding use cases.
Compared to other leading proprietary and open-weights models Command A delivers maximum performance with minimum hardware costs, excelling on business-critical agentic and multilingual tasks. |
| openai/gpt-4o-mini-search-preview | 2025-03-13 | $0.15 | $0.60 | 128,000 | Yes | Yes | No | No | GPT-4o mini Search Preview is a specialized model for web search in Chat Completions. It is trained to understand and execute web search queries. |
| openai/gpt-4o-search-preview | 2025-03-13 | $2.50 | $10.00 | 128,000 | Yes | Yes | No | No | GPT-4o Search Previewis a specialized model for web search in Chat Completions. It is trained to understand and execute web search queries. |
| rekaai/reka-flash-3:free | 2025-03-13 | $0.00 | $0.00 | 32,768 | No | No | Yes | Yes | Reka Flash 3 is a general-purpose, instruction-tuned large language model with 21 billion parameters, developed by Reka. It excels at general chat, coding tasks, instruction-following, and function calling. Featuring a 32K context length and optimized through reinforcement learning (RLOO), it provides competitive performance comparable to proprietary models within a smaller parameter footprint. Ideal for low-latency, local, or on-device deployments, Reka Flash 3 is compact, supports efficient quantization (down to 11GB at 4-bit precision), and employs explicit reasoning tags (“ |
| google/gemma-3-27b-it:free | 2025-03-12 | $0.00 | $0.00 | 96,000 | Yes | Yes | No | No | Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 27B is Google’s latest open source model, successor to [Gemma 2](google/gemma-2-27b-it) |
| google/gemma-3-27b-it | 2025-03-12 | $0.07 | $0.27 | 96,000 | No | Yes | No | No | Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 27B is Google’s latest open source model, successor to [Gemma 2](google/gemma-2-27b-it) |
| thedrummer/anubis-pro-105b-v1 | 2025-03-11 | $0.50 | $1.00 | 131,072 | No | No | No | No | Anubis Pro 105B v1 is an expanded and refined variant of Meta’s Llama 3.3 70B, featuring 50% additional layers and further fine-tuning to leverage its increased capacity. Designed for advanced narrative, roleplay, and instructional tasks, it demonstrates enhanced emotional intelligence, creativity, nuanced character portrayal, and superior prompt adherence compared to smaller models. Its larger parameter count allows for deeper contextual understanding and extended reasoning capabilities, optimized for engaging, intelligent, and coherent interactions. |
| thedrummer/skyfall-36b-v2 | 2025-03-11 | $0.05 | $0.19 | 32,768 | Yes | Yes | No | No | Skyfall 36B v2 is an enhanced iteration of Mistral Small 2501, specifically fine-tuned for improved creativity, nuanced writing, role-playing, and coherent storytelling. |
| microsoft/phi-4-multimodal-instruct | 2025-03-08 | $0.05 | $0.10 | 131,072 | No | Yes | No | No | Phi-4 Multimodal Instruct is a versatile 5.6B parameter foundation model that combines advanced reasoning and instruction-following capabilities across both text and visual inputs, providing accurate text outputs. The unified architecture enables efficient, low-latency inference, suitable for edge and mobile deployments. Phi-4 Multimodal Instruct supports text inputs in multiple languages including Arabic, Chinese, English, French, German, Japanese, Spanish, and more, with visual input optimized primarily for English. It delivers impressive performance on multimodal tasks involving mathematical, scientific, and document reasoning, providing developers and enterprises a powerful yet compact model for sophisticated interactive applications. For more information, see the [Phi-4 Multimodal blog post](https://azure.microsoft.com/en-us/blog/empowering-innovation-the-next-generation-of-the-phi-family/).
|
| perplexity/sonar-reasoning-pro | 2025-03-07 | $2.00 | $8.00 | 128,000 | No | No | Yes | Yes | Note: Sonar Pro pricing includes Perplexity search pricing. See [details here](https://docs.perplexity.ai/guides/pricing#detailed-pricing-breakdown-for-sonar-reasoning-pro-and-sonar-pro)
Sonar Reasoning Pro is a premier reasoning model powered by DeepSeek R1 with Chain of Thought (CoT). Designed for advanced use cases, it supports in-depth, multi-step queries with a larger context window and can surface more citations per search, enabling more comprehensive and extensible responses. |
| perplexity/sonar-pro | 2025-03-07 | $3.00 | $15.00 | 200,000 | No | No | No | No | Note: Sonar Pro pricing includes Perplexity search pricing. See [details here](https://docs.perplexity.ai/guides/pricing#detailed-pricing-breakdown-for-sonar-reasoning-pro-and-sonar-pro)
For enterprises seeking more advanced capabilities, the Sonar Pro API can handle in-depth, multi-step queries with added extensibility, like double the number of citations per search as Sonar on average. Plus, with a larger context window, it can handle longer and more nuanced searches and follow-up questions. |
| perplexity/sonar-deep-research | 2025-03-07 | $2.00 | $8.00 | 128,000 | No | No | Yes | Yes | Sonar Deep Research is a research-focused model designed for multi-step retrieval, synthesis, and reasoning across complex topics. It autonomously searches, reads, and evaluates sources, refining its approach as it gathers information. This enables comprehensive report generation across domains like finance, technology, health, and current events.
Notes on Pricing ([Source](https://docs.perplexity.ai/guides/pricing#detailed-pricing-breakdown-for-sonar-deep-research))
– Input tokens comprise of Prompt tokens (user prompt) + Citation tokens (these are processed tokens from running searches)
– Deep Research runs multiple searches to conduct exhaustive research. Searches are priced at $5/1000 searches. A request that does 30 searches will cost $0.15 in this step.
– Reasoning is a distinct step in Deep Research since it does extensive automated reasoning through all the material it gathers during its research phase. Reasoning tokens here are a bit different than the CoTs in the answer – these are tokens that we use to reason through the research material prior to generating the outputs via the CoTs. Reasoning tokens are priced at $3/1M tokens |
| qwen/qwq-32b:free | 2025-03-06 | $0.00 | $0.00 | 32,768 | Yes | Yes | No | No | QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning, can achieve significantly enhanced performance in downstream tasks, especially hard problems. QwQ-32B is the medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini. |
| qwen/qwq-32b | 2025-03-06 | $0.07 | $0.15 | 131,072 | Yes | Yes | Yes | Yes | QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning, can achieve significantly enhanced performance in downstream tasks, especially hard problems. QwQ-32B is the medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini. |
| nousresearch/deephermes-3-llama-3-8b-preview:free | 2025-02-28 | $0.00 | $0.00 | 131,072 | No | No | No | No | DeepHermes 3 Preview is the latest version of our flagship Hermes series of LLMs by Nous Research, and one of the first models in the world to unify Reasoning (long chains of thought that improve answer accuracy) and normal LLM response modes into one model. We have also improved LLM annotation, judgement, and function calling.
DeepHermes 3 Preview is one of the first LLM models to unify both “intuitive”, traditional mode responses and long chain of thought reasoning responses into a single model, toggled by a system prompt. |
| google/gemini-2.0-flash-lite-001 | 2025-02-25 | $0.07 | $0.30 | 1,048,576 | Yes | Yes | No | No | Gemini 2.0 Flash Lite offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1.5](/google/gemini-flash-1.5), while maintaining quality on par with larger models like [Gemini Pro 1.5](/google/gemini-pro-1.5), all at extremely economical token prices. |
| anthropic/claude-3.7-sonnet | 2025-02-25 | $3.00 | $15.00 | 200,000 | No | No | Yes | Yes | Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes.
Claude 3.7 Sonnet maintains performance parity with its predecessor in standard mode while offering an extended reasoning mode for enhanced accuracy in math, coding, and instruction-following tasks.
Read more at the [blog post here](https://www.anthropic.com/news/claude-3-7-sonnet) |
| anthropic/claude-3.7-sonnet:thinking | 2025-02-25 | $3.00 | $15.00 | 200,000 | No | No | Yes | Yes | Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes.
Claude 3.7 Sonnet maintains performance parity with its predecessor in standard mode while offering an extended reasoning mode for enhanced accuracy in math, coding, and instruction-following tasks.
Read more at the [blog post here](https://www.anthropic.com/news/claude-3-7-sonnet) |
| anthropic/claude-3.7-sonnet:beta | 2025-02-25 | $3.00 | $15.00 | 200,000 | No | No | Yes | Yes | Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes.
Claude 3.7 Sonnet maintains performance parity with its predecessor in standard mode while offering an extended reasoning mode for enhanced accuracy in math, coding, and instruction-following tasks.
Read more at the [blog post here](https://www.anthropic.com/news/claude-3-7-sonnet) |
| perplexity/r1-1776 | 2025-02-20 | $2.00 | $8.00 | 128,000 | No | No | Yes | Yes | R1 1776 is a version of DeepSeek-R1 that has been post-trained to remove censorship constraints related to topics restricted by the Chinese government. The model retains its original reasoning capabilities while providing direct responses to a wider range of queries. R1 1776 is an offline chat model that does not use the perplexity search subsystem.
The model was tested on a multilingual dataset of over 1,000 examples covering sensitive topics to measure its likelihood of refusal or overly filtered responses. [Evaluation Results](https://cdn-uploads.huggingface.co/production/uploads/675c8332d01f593dc90817f5/GiN2VqC5hawUgAGJ6oHla.png) Its performance on math and reasoning benchmarks remains similar to the base R1 model. [Reasoning Performance](https://cdn-uploads.huggingface.co/production/uploads/675c8332d01f593dc90817f5/n4Z9Byqp2S7sKUvCvI40R.png)
Read more on the [Blog Post](https://perplexity.ai/hub/blog/open-sourcing-r1-1776) |
| mistralai/mistral-saba | 2025-02-17 | $0.20 | $0.60 | 32,768 | Yes | Yes | No | No | Mistral Saba is a 24B-parameter language model specifically designed for the Middle East and South Asia, delivering accurate and contextually relevant responses while maintaining efficient performance. Trained on curated regional datasets, it supports multiple Indian-origin languages—including Tamil and Malayalam—alongside Arabic. This makes it a versatile option for a range of regional and multilingual applications. Read more at the blog post [here](https://mistral.ai/en/news/mistral-saba) |
| cognitivecomputations/dolphin3.0-r1-mistral-24b:free | 2025-02-13 | $0.00 | $0.00 | 32,768 | No | No | Yes | Yes | Dolphin 3.0 R1 is the next generation of the Dolphin series of instruct-tuned models. Designed to be the ultimate general purpose local model, enabling coding, math, agentic, function calling, and general use cases.
The R1 version has been trained for 3 epochs to reason using 800k reasoning traces from the Dolphin-R1 dataset.
Dolphin aims to be a general purpose reasoning instruct model, similar to the models behind ChatGPT, Claude, Gemini.
Part of the [Dolphin 3.0 Collection](https://huggingface.co/collections/cognitivecomputations/dolphin-30-677ab47f73d7ff66743979a3) Curated and trained by [Eric Hartford](https://huggingface.co/ehartford), [Ben Gitter](https://huggingface.co/bigstorm), [BlouseJury](https://huggingface.co/BlouseJury) and [Cognitive Computations](https://huggingface.co/cognitivecomputations) |
| cognitivecomputations/dolphin3.0-r1-mistral-24b | 2025-02-13 | $0.01 | $0.03 | 32,768 | No | No | Yes | Yes | Dolphin 3.0 R1 is the next generation of the Dolphin series of instruct-tuned models. Designed to be the ultimate general purpose local model, enabling coding, math, agentic, function calling, and general use cases.
The R1 version has been trained for 3 epochs to reason using 800k reasoning traces from the Dolphin-R1 dataset.
Dolphin aims to be a general purpose reasoning instruct model, similar to the models behind ChatGPT, Claude, Gemini.
Part of the [Dolphin 3.0 Collection](https://huggingface.co/collections/cognitivecomputations/dolphin-30-677ab47f73d7ff66743979a3) Curated and trained by [Eric Hartford](https://huggingface.co/ehartford), [Ben Gitter](https://huggingface.co/bigstorm), [BlouseJury](https://huggingface.co/BlouseJury) and [Cognitive Computations](https://huggingface.co/cognitivecomputations) |
| cognitivecomputations/dolphin3.0-mistral-24b:free | 2025-02-13 | $0.00 | $0.00 | 32,768 | No | No | No | No | Dolphin 3.0 is the next generation of the Dolphin series of instruct-tuned models. Designed to be the ultimate general purpose local model, enabling coding, math, agentic, function calling, and general use cases.
Dolphin aims to be a general purpose instruct model, similar to the models behind ChatGPT, Claude, Gemini.
Part of the [Dolphin 3.0 Collection](https://huggingface.co/collections/cognitivecomputations/dolphin-30-677ab47f73d7ff66743979a3) Curated and trained by [Eric Hartford](https://huggingface.co/ehartford), [Ben Gitter](https://huggingface.co/bigstorm), [BlouseJury](https://huggingface.co/BlouseJury) and [Cognitive Computations](https://huggingface.co/cognitivecomputations) |
| cognitivecomputations/dolphin3.0-mistral-24b | 2025-02-13 | $0.04 | $0.15 | 32,768 | No | No | No | No | Dolphin 3.0 is the next generation of the Dolphin series of instruct-tuned models. Designed to be the ultimate general purpose local model, enabling coding, math, agentic, function calling, and general use cases.
Dolphin aims to be a general purpose instruct model, similar to the models behind ChatGPT, Claude, Gemini.
Part of the [Dolphin 3.0 Collection](https://huggingface.co/collections/cognitivecomputations/dolphin-30-677ab47f73d7ff66743979a3) Curated and trained by [Eric Hartford](https://huggingface.co/ehartford), [Ben Gitter](https://huggingface.co/bigstorm), [BlouseJury](https://huggingface.co/BlouseJury) and [Cognitive Computations](https://huggingface.co/cognitivecomputations) |
| meta-llama/llama-guard-3-8b | 2025-02-13 | $0.02 | $0.06 | 131,072 | No | Yes | No | No | Llama Guard 3 is a Llama-3.1-8B pretrained model, fine-tuned for content safety classification. Similar to previous versions, it can be used to classify content in both LLM inputs (prompt classification) and in LLM responses (response classification). It acts as an LLM – it generates text in its output that indicates whether a given prompt or response is safe or unsafe, and if unsafe, it also lists the content categories violated.
Llama Guard 3 was aligned to safeguard against the MLCommons standardized hazards taxonomy and designed to support Llama 3.1 capabilities. Specifically, it provides content moderation in 8 languages, and was optimized to support safety and security for search and code interpreter tool calls.
|
| openai/o3-mini-high | 2025-02-12 | $1.10 | $4.40 | 200,000 | Yes | Yes | No | No | OpenAI o3-mini-high is the same model as [o3-mini](/openai/o3-mini) with reasoning_effort set to high.
o3-mini is a cost-efficient language model optimized for STEM reasoning tasks, particularly excelling in science, mathematics, and coding. The model features three adjustable reasoning effort levels and supports key developer capabilities including function calling, structured outputs, and streaming, though it does not include vision processing capabilities.
The model demonstrates significant improvements over its predecessor, with expert testers preferring its responses 56% of the time and noting a 39% reduction in major errors on complex questions. With medium reasoning effort settings, o3-mini matches the performance of the larger o1 model on challenging reasoning evaluations like AIME and GPQA, while maintaining lower latency and cost. |
| deepseek/deepseek-r1-distill-llama-8b | 2025-02-07 | $0.04 | $0.04 | 32,000 | No | No | Yes | Yes | DeepSeek R1 Distill Llama 8B is a distilled large language model based on [Llama-3.1-8B-Instruct](/meta-llama/llama-3.1-8b-instruct), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). The model combines advanced distillation techniques to achieve high performance across multiple benchmarks, including:
– AIME 2024 pass@1: 50.4
– MATH-500 pass@1: 89.1
– CodeForces Rating: 1205
The model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models.
Hugging Face:
– [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B)
– [DeepSeek-R1-Distill-Llama-8B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) | |
| google/gemini-2.0-flash-001 | 2025-02-05 | $0.10 | $0.40 | 1,048,576 | Yes | Yes | No | No | Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1.5](/google/gemini-flash-1.5), while maintaining quality on par with larger models like [Gemini Pro 1.5](/google/gemini-pro-1.5). It introduces notable enhancements in multimodal understanding, coding capabilities, complex instruction following, and function calling. These advancements come together to deliver more seamless and robust agentic experiences. |
| qwen/qwen-vl-plus | 2025-02-05 | $0.21 | $0.63 | 7,500 | No | Yes | No | No | Qwen’s Enhanced Large Visual Language Model. Significantly upgraded for detailed recognition capabilities and text recognition abilities, supporting ultra-high pixel resolutions up to millions of pixels and extreme aspect ratios for image input. It delivers significant performance across a broad range of visual tasks.
|
| aion-labs/aion-1.0 | 2025-02-05 | $4.00 | $8.00 | 131,072 | No | No | Yes | Yes | Aion-1.0 is a multi-model system designed for high performance across various tasks, including reasoning and coding. It is built on DeepSeek-R1, augmented with additional models and techniques such as Tree of Thoughts (ToT) and Mixture of Experts (MoE). It is Aion Lab’s most powerful reasoning model. |
| aion-labs/aion-1.0-mini | 2025-02-05 | $0.70 | $1.40 | 131,072 | No | No | Yes | Yes | Aion-1.0-Mini 32B parameter model is a distilled version of the DeepSeek-R1 model, designed for strong performance in reasoning domains such as mathematics, coding, and logic. It is a modified variant of a FuseAI model that outperforms R1-Distill-Qwen-32B and R1-Distill-Llama-70B, with benchmark results available on its [Hugging Face page](https://huggingface.co/FuseAI/FuseO1-DeepSeekR1-QwQ-SkyT1-32B-Preview), independently replicated for verification. |
| aion-labs/aion-rp-llama-3.1-8b | 2025-02-05 | $0.20 | $0.20 | 32,768 | No | No | No | No | Aion-RP-Llama-3.1-8B ranks the highest in the character evaluation portion of the RPBench-Auto benchmark, a roleplaying-specific variant of Arena-Hard-Auto, where LLMs evaluate each other’s responses. It is a fine-tuned base model rather than an instruct model, designed to produce more natural and varied writing. |
| qwen/qwen-vl-max | 2025-02-01 | $0.80 | $3.20 | 7,500 | No | Yes | No | No | Qwen VL Max is a visual understanding model with 7500 tokens context length. It excels in delivering optimal performance for a broader spectrum of complex tasks.
|
| qwen/qwen-turbo | 2025-02-01 | $0.05 | $0.20 | 1,000,000 | No | Yes | No | No | Qwen-Turbo, based on Qwen2.5, is a 1M context model that provides fast speed and low cost, suitable for simple tasks. |
| qwen/qwen2.5-vl-72b-instruct:free | 2025-02-01 | $0.00 | $0.00 | 32,768 | Yes | Yes | No | No | Qwen2.5-VL is proficient in recognizing common objects such as flowers, birds, fish, and insects. It is also highly capable of analyzing texts, charts, icons, graphics, and layouts within images. |
| qwen/qwen2.5-vl-72b-instruct | 2025-02-01 | $0.10 | $0.40 | 32,768 | No | No | No | No | Qwen2.5-VL is proficient in recognizing common objects such as flowers, birds, fish, and insects. It is also highly capable of analyzing texts, charts, icons, graphics, and layouts within images. |
| qwen/qwen-plus | 2025-02-01 | $0.40 | $1.20 | 131,072 | No | Yes | No | No | Qwen-Plus, based on the Qwen2.5 foundation model, is a 131K context model with a balanced performance, speed, and cost combination. |
| qwen/qwen-max | 2025-02-01 | $1.60 | $6.40 | 32,768 | No | Yes | No | No | Qwen-Max, based on Qwen2.5, provides the best inference performance among [Qwen models](/qwen), especially for complex multi-step tasks. It’s a large-scale MoE model that has been pretrained on over 20 trillion tokens and further post-trained with curated Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) methodologies. The parameter count is unknown. |
| openai/o3-mini | 2025-02-01 | $1.10 | $4.40 | 200,000 | Yes | Yes | No | No | OpenAI o3-mini is a cost-efficient language model optimized for STEM reasoning tasks, particularly excelling in science, mathematics, and coding.
This model supports the `reasoning_effort` parameter, which can be set to “high”, “medium”, or “low” to control the thinking time of the model. The default is “medium”. OpenRouter also offers the model slug `openai/o3-mini-high` to default the parameter to “high”.
The model features three adjustable reasoning effort levels and supports key developer capabilities including function calling, structured outputs, and streaming, though it does not include vision processing capabilities.
The model demonstrates significant improvements over its predecessor, with expert testers preferring its responses 56% of the time and noting a 39% reduction in major errors on complex questions. With medium reasoning effort settings, o3-mini matches the performance of the larger o1 model on challenging reasoning evaluations like AIME and GPQA, while maintaining lower latency and cost. |
| deepseek/deepseek-r1-distill-qwen-1.5b | 2025-01-31 | $0.18 | $0.18 | 131,072 | No | No | Yes | Yes | DeepSeek R1 Distill Qwen 1.5B is a distilled large language model based on [Qwen 2.5 Math 1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). It’s a very small and efficient model which outperforms [GPT 4o 0513](/openai/gpt-4o-2024-05-13) on Math Benchmarks.
Other benchmark results include:
– AIME 2024 pass@1: 28.9
– AIME 2024 cons@64: 52.7
– MATH-500 pass@1: 83.9
The model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models. |
| mistralai/mistral-small-24b-instruct-2501:free | 2025-01-30 | $0.00 | $0.00 | 32,768 | No | No | No | No | Mistral Small 3 is a 24B-parameter language model optimized for low-latency performance across common AI tasks. Released under the Apache 2.0 license, it features both pre-trained and instruction-tuned versions designed for efficient local deployment.
The model achieves 81% accuracy on the MMLU benchmark and performs competitively with larger models like Llama 3.3 70B and Qwen 32B, while operating at three times the speed on equivalent hardware. [Read the blog post about the model here.](https://mistral.ai/news/mistral-small-3/) |
| mistralai/mistral-small-24b-instruct-2501 | 2025-01-30 | $0.02 | $0.08 | 32,768 | Yes | Yes | No | No | Mistral Small 3 is a 24B-parameter language model optimized for low-latency performance across common AI tasks. Released under the Apache 2.0 license, it features both pre-trained and instruction-tuned versions designed for efficient local deployment.
The model achieves 81% accuracy on the MMLU benchmark and performs competitively with larger models like Llama 3.3 70B and Qwen 32B, while operating at three times the speed on equivalent hardware. [Read the blog post about the model here.](https://mistral.ai/news/mistral-small-3/) |
| deepseek/deepseek-r1-distill-qwen-32b | 2025-01-30 | $0.07 | $0.15 | 131,072 | No | Yes | Yes | Yes | DeepSeek R1 Distill Qwen 32B is a distilled large language model based on [Qwen 2.5 32B](https://huggingface.co/Qwen/Qwen2.5-32B), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). It outperforms OpenAI’s o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.\n\nOther benchmark results include:\n\n- AIME 2024 pass@1: 72.6\n- MATH-500 pass@1: 94.3\n- CodeForces Rating: 1691\n\nThe model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models. |
| deepseek/deepseek-r1-distill-qwen-14b:free | 2025-01-30 | $0.00 | $0.00 | 64,000 | No | No | Yes | Yes | DeepSeek R1 Distill Qwen 14B is a distilled large language model based on [Qwen 2.5 14B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). It outperforms OpenAI’s o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
Other benchmark results include:
– AIME 2024 pass@1: 69.7
– MATH-500 pass@1: 93.9
– CodeForces Rating: 1481
The model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models. |
| deepseek/deepseek-r1-distill-qwen-14b | 2025-01-30 | $0.15 | $0.15 | 64,000 | No | No | Yes | Yes | DeepSeek R1 Distill Qwen 14B is a distilled large language model based on [Qwen 2.5 14B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). It outperforms OpenAI’s o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
Other benchmark results include:
– AIME 2024 pass@1: 69.7
– MATH-500 pass@1: 93.9
– CodeForces Rating: 1481
The model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models. |
| perplexity/sonar-reasoning | 2025-01-29 | $1.00 | $5.00 | 127,000 | No | No | Yes | Yes | Sonar Reasoning is a reasoning model provided by Perplexity based on [DeepSeek R1](/deepseek/deepseek-r1).
It allows developers to utilize long chain of thought with built-in web search. Sonar Reasoning is uncensored and hosted in US datacenters. |
| perplexity/sonar | 2025-01-28 | $1.00 | $1.00 | 127,072 | No | No | No | No | Sonar is lightweight, affordable, fast, and simple to use — now featuring citations and the ability to customize sources. It is designed for companies seeking to integrate lightweight question-and-answer features optimized for speed. |
| liquid/lfm-7b | 2025-01-25 | $0.01 | $0.01 | 32,768 | No | Yes | No | No | LFM-7B, a new best-in-class language model. LFM-7B is designed for exceptional chat capabilities, including languages like Arabic and Japanese. Powered by the Liquid Foundation Model (LFM) architecture, it exhibits unique features like low memory footprint and fast inference speed.
LFM-7B is the world’s best-in-class multilingual language model in English, Arabic, and Japanese.
See the [launch announcement](https://www.liquid.ai/lfm-7b) for benchmarks and more info. |
| liquid/lfm-3b | 2025-01-25 | $0.02 | $0.02 | 32,768 | No | No | No | No | Liquid’s LFM 3B delivers incredible performance for its size. It positions itself as first place among 3B parameter transformers, hybrids, and RNN models It is also on par with Phi-3.5-mini on multiple benchmarks, while being 18.4% smaller.
LFM-3B is the ideal choice for mobile and other edge text-based applications.
See the [launch announcement](https://www.liquid.ai/liquid-foundation-models) for benchmarks and more info. |
| deepseek/deepseek-r1-distill-llama-70b:free | 2025-01-24 | $0.00 | $0.00 | 8,192 | No | No | Yes | Yes | DeepSeek R1 Distill Llama 70B is a distilled large language model based on [Llama-3.3-70B-Instruct](/meta-llama/llama-3.3-70b-instruct), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). The model combines advanced distillation techniques to achieve high performance across multiple benchmarks, including:
– AIME 2024 pass@1: 70.0
– MATH-500 pass@1: 94.5
– CodeForces Rating: 1633
The model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models. |
| deepseek/deepseek-r1-distill-llama-70b | 2025-01-24 | $0.03 | $0.13 | 131,072 | Yes | Yes | Yes | Yes | DeepSeek R1 Distill Llama 70B is a distilled large language model based on [Llama-3.3-70B-Instruct](/meta-llama/llama-3.3-70b-instruct), using outputs from [DeepSeek R1](/deepseek/deepseek-r1). The model combines advanced distillation techniques to achieve high performance across multiple benchmarks, including:
– AIME 2024 pass@1: 70.0
– MATH-500 pass@1: 94.5
– CodeForces Rating: 1633
The model leverages fine-tuning from DeepSeek R1’s outputs, enabling competitive performance comparable to larger frontier models. |
| deepseek/deepseek-r1:free | 2025-01-20 | $0.00 | $0.00 | 163,840 | No | No | Yes | Yes | DeepSeek R1 is here: Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It’s 671B parameters in size, with 37B active in an inference pass.
Fully open-source model & [technical report](https://api-docs.deepseek.com/news/news250120).
MIT licensed: Distill & commercialize freely! |
| deepseek/deepseek-r1 | 2025-01-20 | $0.40 | $2.00 | 163,840 | Yes | Yes | Yes | Yes | DeepSeek R1 is here: Performance on par with [OpenAI o1](/openai/o1), but open-sourced and with fully open reasoning tokens. It’s 671B parameters in size, with 37B active in an inference pass.
Fully open-source model & [technical report](https://api-docs.deepseek.com/news/news250120).
MIT licensed: Distill & commercialize freely! |
| minimax/minimax-01 | 2025-01-15 | $0.20 | $1.10 | 1,000,192 | No | No | No | No | MiniMax-01 is a combines MiniMax-Text-01 for text generation and MiniMax-VL-01 for image understanding. It has 456 billion parameters, with 45.9 billion parameters activated per inference, and can handle a context of up to 4 million tokens.
The text model adopts a hybrid architecture that combines Lightning Attention, Softmax Attention, and Mixture-of-Experts (MoE). The image model adopts the “ViT-MLP-LLM” framework and is trained on top of the text model.
To read more about the release, see: https://www.minimaxi.com/en/news/minimax-01-series-2 |
| mistralai/codestral-2501 | 2025-01-15 | $0.30 | $0.90 | 262,144 | Yes | Yes | No | No | [Mistral](/mistralai)’s cutting-edge language model for coding. Codestral specializes in low-latency, high-frequency tasks such as fill-in-the-middle (FIM), code correction and test generation.
Learn more on their blog post: https://mistral.ai/news/codestral-2501/ |
| microsoft/phi-4 | 2025-01-10 | $0.06 | $0.14 | 16,384 | Yes | Yes | No | No | [Microsoft Research](/microsoft) Phi-4 is designed to perform well in complex reasoning tasks and can operate efficiently in situations with limited memory or where quick responses are needed.
At 14 billion parameters, it was trained on a mix of high-quality synthetic datasets, data from curated websites, and academic materials. It has undergone careful improvement to follow instructions accurately and maintain strong safety standards. It works best with English language inputs.
For more information, please see [Phi-4 Technical Report](https://arxiv.org/pdf/2412.08905)
|
| deepseek/deepseek-chat | 2024-12-27 | $0.18 | $0.72 | 163,840 | Yes | Yes | No | No | DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-trained on nearly 15 trillion tokens, the reported evaluations reveal that the model outperforms other open-source models and rivals leading closed-source models.
For model details, please visit [the DeepSeek-V3 repo](https://github.com/deepseek-ai/DeepSeek-V3) for more information, or see the [launch announcement](https://api-docs.deepseek.com/news/news1226). |
| sao10k/l3.3-euryale-70b | 2024-12-18 | $0.65 | $0.75 | 131,072 | Yes | Yes | No | No | Euryale L3.3 70B is a model focused on creative roleplay from [Sao10k](https://ko-fi.com/sao10k). It is the successor of [Euryale L3 70B v2.2](/models/sao10k/l3-euryale-70b). |
| openai/o1 | 2024-12-17 | $15.00 | $60.00 | 200,000 | Yes | Yes | No | No | The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought.
The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the [launch announcement](https://openai.com/o1).
|
| x-ai/grok-2-vision-1212 | 2024-12-15 | $2.00 | $10.00 | 32,768 | No | Yes | No | No | Grok 2 Vision 1212 advances image-based AI with stronger visual comprehension, refined instruction-following, and multilingual support. From object recognition to style analysis, it empowers developers to build more intuitive, visually aware applications. Its enhanced steerability and reasoning establish a robust foundation for next-generation image solutions.
To read more about this model, check out [xAI’s announcement](https://x.ai/blog/grok-1212). |
| x-ai/grok-2-1212 | 2024-12-15 | $2.00 | $10.00 | 131,072 | No | Yes | No | No | Grok 2 1212 introduces significant enhancements to accuracy, instruction adherence, and multilingual support, making it a powerful and flexible choice for developers seeking a highly steerable, intelligent model. |
| cohere/command-r7b-12-2024 | 2024-12-14 | $0.04 | $0.15 | 128,000 | Yes | Yes | No | No | Command R7B (12-2024) is a small, fast update of the Command R+ model, delivered in December 2024. It excels at RAG, tool use, agents, and similar tasks requiring complex reasoning and multiple steps.
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| google/gemini-2.0-flash-exp:free | 2024-12-11 | $0.00 | $0.00 | 1,048,576 | No | Yes | No | No | Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to [Gemini Flash 1.5](/google/gemini-flash-1.5), while maintaining quality on par with larger models like [Gemini Pro 1.5](/google/gemini-pro-1.5). It introduces notable enhancements in multimodal understanding, coding capabilities, complex instruction following, and function calling. These advancements come together to deliver more seamless and robust agentic experiences. |
| meta-llama/llama-3.3-70b-instruct:free | 2024-12-06 | $0.00 | $0.00 | 65,536 | No | No | No | No | The Meta Llama 3.3 multilingual large language model (LLM) is a pretrained and instruction tuned generative model in 70B (text in/text out). The Llama 3.3 instruction tuned text only model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks.
Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
[Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_3/MODEL_CARD.md) |
| meta-llama/llama-3.3-70b-instruct | 2024-12-06 | $0.04 | $0.12 | 131,072 | Yes | Yes | No | No | The Meta Llama 3.3 multilingual large language model (LLM) is a pretrained and instruction tuned generative model in 70B (text in/text out). The Llama 3.3 instruction tuned text only model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks.
Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
[Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_3/MODEL_CARD.md) |
| amazon/nova-lite-v1 | 2024-12-06 | $0.06 | $0.24 | 300,000 | No | No | No | No | Amazon Nova Lite 1.0 is a very low-cost multimodal model from Amazon that focused on fast processing of image, video, and text inputs to generate text output. Amazon Nova Lite can handle real-time customer interactions, document analysis, and visual question-answering tasks with high accuracy.
With an input context of 300K tokens, it can analyze multiple images or up to 30 minutes of video in a single input. |
| amazon/nova-micro-v1 | 2024-12-06 | $0.04 | $0.14 | 128,000 | No | No | No | No | Amazon Nova Micro 1.0 is a text-only model that delivers the lowest latency responses in the Amazon Nova family of models at a very low cost. With a context length of 128K tokens and optimized for speed and cost, Amazon Nova Micro excels at tasks such as text summarization, translation, content classification, interactive chat, and brainstorming. It has simple mathematical reasoning and coding abilities. |
| amazon/nova-pro-v1 | 2024-12-06 | $0.80 | $3.20 | 300,000 | No | No | No | No | Amazon Nova Pro 1.0 is a capable multimodal model from Amazon focused on providing a combination of accuracy, speed, and cost for a wide range of tasks. As of December 2024, it achieves state-of-the-art performance on key benchmarks including visual question answering (TextVQA) and video understanding (VATEX).
Amazon Nova Pro demonstrates strong capabilities in processing both visual and textual information and at analyzing financial documents.
**NOTE**: Video input is not supported at this time. |
| qwen/qwq-32b-preview | 2024-11-28 | $0.20 | $0.20 | 32,768 | No | No | No | No | QwQ-32B-Preview is an experimental research model focused on AI reasoning capabilities developed by the Qwen Team. As a preview release, it demonstrates promising analytical abilities while having several important limitations:
1. **Language Mixing and Code-Switching**: The model may mix languages or switch between them unexpectedly, affecting response clarity.
2. **Recursive Reasoning Loops**: The model may enter circular reasoning patterns, leading to lengthy responses without a conclusive answer.
3. **Safety and Ethical Considerations**: The model requires enhanced safety measures to ensure reliable and secure performance, and users should exercise caution when deploying it.
4. **Performance and Benchmark Limitations**: The model excels in math and coding but has room for improvement in other areas, such as common sense reasoning and nuanced language understanding.
|
| openai/gpt-4o-2024-11-20 | 2024-11-21 | $2.50 | $10.00 | 128,000 | Yes | Yes | No | No | The 2024-11-20 version of GPT-4o offers a leveled-up creative writing ability with more natural, engaging, and tailored writing to improve relevance & readability. It’s also better at working with uploaded files, providing deeper insights & more thorough responses.
GPT-4o (“o” for “omni”) is OpenAI’s latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/openai/gpt-4-turbo) while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. |
| mistralai/mistral-large-2411 | 2024-11-19 | $2.00 | $6.00 | 131,072 | Yes | Yes | No | No | Mistral Large 2 2411 is an update of [Mistral Large 2](/mistralai/mistral-large) released together with [Pixtral Large 2411](/mistralai/pixtral-large-2411)
It provides a significant upgrade on the previous [Mistral Large 24.07](/mistralai/mistral-large-2407), with notable improvements in long context understanding, a new system prompt, and more accurate function calling. |
| mistralai/mistral-large-2407 | 2024-11-19 | $2.00 | $6.00 | 131,072 | Yes | Yes | No | No | This is Mistral AI’s flagship model, Mistral Large 2 (version mistral-large-2407). It’s a proprietary weights-available model and excels at reasoning, code, JSON, chat, and more. Read the launch announcement [here](https://mistral.ai/news/mistral-large-2407/).
It supports dozens of languages including French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80+ coding languages including Python, Java, C, C++, JavaScript, and Bash. Its long context window allows precise information recall from large documents.
|
| mistralai/pixtral-large-2411 | 2024-11-19 | $2.00 | $6.00 | 131,072 | Yes | Yes | No | No | Pixtral Large is a 124B parameter, open-weight, multimodal model built on top of [Mistral Large 2](/mistralai/mistral-large-2411). The model is able to understand documents, charts and natural images.
The model is available under the Mistral Research License (MRL) for research and educational use, and the Mistral Commercial License for experimentation, testing, and production for commercial purposes.
|
| x-ai/grok-vision-beta | 2024-11-19 | $5.00 | $15.00 | 8,192 | No | Yes | No | No | Grok Vision Beta is xAI’s experimental language model with vision capability.
|
| infermatic/mn-inferor-12b | 2024-11-13 | $0.60 | $1.00 | 8,192 | No | No | No | No | Inferor 12B is a merge of top roleplay models, expert on immersive narratives and storytelling.
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [anthracite-org/magnum-v4-12b](https://openrouter.ai/anthracite-org/magnum-v4-72b) as a base.
|
| qwen/qwen-2.5-coder-32b-instruct:free | 2024-11-12 | $0.00 | $0.00 | 32,768 | No | No | No | No | Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:
– Significantly improvements in **code generation**, **code reasoning** and **code fixing**.
– A more comprehensive foundation for real-world applications such as **Code Agents**. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
To read more about its evaluation results, check out [Qwen 2.5 Coder’s blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/). |
| qwen/qwen-2.5-coder-32b-instruct | 2024-11-12 | $0.05 | $0.20 | 32,768 | No | Yes | No | No | Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:
– Significantly improvements in **code generation**, **code reasoning** and **code fixing**.
– A more comprehensive foundation for real-world applications such as **Code Agents**. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies.
To read more about its evaluation results, check out [Qwen 2.5 Coder’s blog](https://qwenlm.github.io/blog/qwen2.5-coder-family/). |
| raifle/sorcererlm-8x22b | 2024-11-09 | $4.50 | $4.50 | 16,000 | No | No | No | No | SorcererLM is an advanced RP and storytelling model, built as a Low-rank 16-bit LoRA fine-tuned on [WizardLM-2 8x22B](/microsoft/wizardlm-2-8x22b).
– Advanced reasoning and emotional intelligence for engaging and immersive interactions
– Vivid writing capabilities enriched with spatial and contextual awareness
– Enhanced narrative depth, promoting creative and dynamic storytelling |
| thedrummer/unslopnemo-12b | 2024-11-09 | $0.40 | $0.40 | 32,768 | Yes | Yes | No | No | UnslopNemo v4.1 is the latest addition from the creator of Rocinante, designed for adventure writing and role-play scenarios. |
| anthropic/claude-3.5-haiku | 2024-11-04 | $0.80 | $4.00 | 200,000 | No | No | No | No | Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Engineered to excel in real-time applications, it delivers quick response times that are essential for dynamic tasks such as chat interactions and immediate coding suggestions.
This makes it highly suitable for environments that demand both speed and precision, such as software development, customer service bots, and data management systems.
This model is currently pointing to [Claude 3.5 Haiku (2024-10-22)](/anthropic/claude-3-5-haiku-20241022). |
| anthropic/claude-3.5-haiku-20241022 | 2024-11-04 | $0.80 | $4.00 | 200,000 | No | No | No | No | Claude 3.5 Haiku features enhancements across all skill sets including coding, tool use, and reasoning. As the fastest model in the Anthropic lineup, it offers rapid response times suitable for applications that require high interactivity and low latency, such as user-facing chatbots and on-the-fly code completions. It also excels in specialized tasks like data extraction and real-time content moderation, making it a versatile tool for a broad range of industries.
It does not support image inputs.
See the launch announcement and benchmark results [here](https://www.anthropic.com/news/3-5-models-and-computer-use) |
| anthracite-org/magnum-v4-72b | 2024-10-22 | $2.50 | $3.00 | 16,384 | No | No | No | No | This is a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet(https://openrouter.ai/anthropic/claude-3.5-sonnet) and Opus(https://openrouter.ai/anthropic/claude-3-opus).
The model is fine-tuned on top of [Qwen2.5 72B](https://openrouter.ai/qwen/qwen-2.5-72b-instruct). |
| anthropic/claude-3.5-sonnet | 2024-10-22 | $3.00 | $15.00 | 200,000 | No | No | No | No | New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:
– Coding: Scores ~49% on SWE-Bench Verified, higher than the last best score, and without any fancy prompt scaffolding
– Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights
– Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone
– Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems)
#multimodal |
| mistralai/ministral-8b | 2024-10-17 | $0.10 | $0.10 | 128,000 | Yes | Yes | No | No | Ministral 8B is an 8B parameter model featuring a unique interleaved sliding-window attention pattern for faster, memory-efficient inference. Designed for edge use cases, it supports up to 128k context length and excels in knowledge and reasoning tasks. It outperforms peers in the sub-10B category, making it perfect for low-latency, privacy-first applications. |
| mistralai/ministral-3b | 2024-10-17 | $0.04 | $0.04 | 32,768 | Yes | Yes | No | No | Ministral 3B is a 3B parameter model optimized for on-device and edge computing. It excels in knowledge, commonsense reasoning, and function-calling, outperforming larger models like Mistral 7B on most benchmarks. Supporting up to 128k context length, it’s ideal for orchestrating agentic workflows and specialist tasks with efficient inference. |
| qwen/qwen-2.5-7b-instruct | 2024-10-16 | $0.04 | $0.10 | 65,536 | Yes | Yes | No | No | Qwen2.5 7B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:
– Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.
– Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.
– Long-context Support up to 128K tokens and can generate up to 8K tokens.
– Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
Usage of this model is subject to [Tongyi Qianwen LICENSE AGREEMENT](https://huggingface.co/Qwen/Qwen1.5-110B-Chat/blob/main/LICENSE). |
| nvidia/llama-3.1-nemotron-70b-instruct | 2024-10-15 | $0.12 | $0.30 | 131,072 | No | Yes | No | No | NVIDIA’s Llama 3.1 Nemotron 70B is a language model designed for generating precise and useful responses. Leveraging [Llama 3.1 70B](/models/meta-llama/llama-3.1-70b-instruct) architecture and Reinforcement Learning from Human Feedback (RLHF), it excels in automatic alignment benchmarks. This model is tailored for applications requiring high accuracy in helpfulness and response generation, suitable for diverse user queries across multiple domains.
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| inflection/inflection-3-productivity | 2024-10-11 | $2.50 | $10.00 | 8,000 | No | No | No | No | Inflection 3 Productivity is optimized for following instructions. It is better for tasks requiring JSON output or precise adherence to provided guidelines. It has access to recent news.
For emotional intelligence similar to Pi, see [Inflect 3 Pi](/inflection/inflection-3-pi)
See [Inflection’s announcement](https://inflection.ai/blog/enterprise) for more details. |
| inflection/inflection-3-pi | 2024-10-11 | $2.50 | $10.00 | 8,000 | No | No | No | No | Inflection 3 Pi powers Inflection’s [Pi](https://pi.ai) chatbot, including backstory, emotional intelligence, productivity, and safety. It has access to recent news, and excels in scenarios like customer support and roleplay.
Pi has been trained to mirror your tone and style, if you use more emojis, so will Pi! Try experimenting with various prompts and conversation styles. |
| google/gemini-flash-1.5-8b | 2024-10-03 | $0.04 | $0.15 | 1,000,000 | Yes | Yes | No | No | Gemini Flash 1.5 8B is optimized for speed and efficiency, offering enhanced performance in small prompt tasks like chat, transcription, and translation. With reduced latency, it is highly effective for real-time and large-scale operations. This model focuses on cost-effective solutions while maintaining high-quality results.
[Click here to learn more about this model](https://developers.googleblog.com/en/gemini-15-flash-8b-is-now-generally-available-for-use/).
Usage of Gemini is subject to Google’s [Gemini Terms of Use](https://ai.google.dev/terms). |
| thedrummer/rocinante-12b | 2024-09-30 | $0.19 | $0.45 | 8,192 | Yes | Yes | No | No | Rocinante 12B is designed for engaging storytelling and rich prose.
Early testers have reported:
– Expanded vocabulary with unique and expressive word choices
– Enhanced creativity for vivid narratives
– Adventure-filled and captivating stories |
| anthracite-org/magnum-v2-72b | 2024-09-30 | $3.00 | $3.00 | 32,768 | No | No | No | No | From the maker of [Goliath](https://openrouter.ai/models/alpindale/goliath-120b), Magnum 72B is the seventh in a family of models designed to achieve the prose quality of the Claude 3 models, notably Opus & Sonnet.
The model is based on [Qwen2 72B](https://openrouter.ai/models/qwen/qwen-2-72b-instruct) and trained with 55 million tokens of highly curated roleplay (RP) data. |
| liquid/lfm-40b | 2024-09-30 | $0.15 | $0.15 | 65,536 | No | Yes | No | No | Liquid’s 40.3B Mixture of Experts (MoE) model. Liquid Foundation Models (LFMs) are large neural networks built with computational units rooted in dynamic systems.
LFMs are general-purpose AI models that can be used to model any kind of sequential data, including video, audio, text, time series, and signals.
See the [launch announcement](https://www.liquid.ai/liquid-foundation-models) for benchmarks and more info. |
| meta-llama/llama-3.2-3b-instruct:free | 2024-09-25 | $0.00 | $0.00 | 131,072 | No | No | No | No | Llama 3.2 3B is a 3-billion-parameter multilingual large language model, optimized for advanced natural language processing tasks like dialogue generation, reasoning, and summarization. Designed with the latest transformer architecture, it supports eight languages, including English, Spanish, and Hindi, and is adaptable for additional languages.
Trained on 9 trillion tokens, the Llama 3.2 3B model excels in instruction-following, complex reasoning, and tool use. Its balanced performance makes it ideal for applications needing accuracy and efficiency in text generation across multilingual settings.
Click here for the [original model card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md).
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| meta-llama/llama-3.2-3b-instruct | 2024-09-25 | $0.00 | $0.01 | 20,000 | Yes | Yes | No | No | Llama 3.2 3B is a 3-billion-parameter multilingual large language model, optimized for advanced natural language processing tasks like dialogue generation, reasoning, and summarization. Designed with the latest transformer architecture, it supports eight languages, including English, Spanish, and Hindi, and is adaptable for additional languages.
Trained on 9 trillion tokens, the Llama 3.2 3B model excels in instruction-following, complex reasoning, and tool use. Its balanced performance makes it ideal for applications needing accuracy and efficiency in text generation across multilingual settings.
Click here for the [original model card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md).
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| meta-llama/llama-3.2-1b-instruct | 2024-09-25 | $0.01 | $0.01 | 131,072 | Yes | Yes | No | No | Llama 3.2 1B is a 1-billion-parameter language model focused on efficiently performing natural language tasks, such as summarization, dialogue, and multilingual text analysis. Its smaller size allows it to operate efficiently in low-resource environments while maintaining strong task performance.
Supporting eight core languages and fine-tunable for more, Llama 1.3B is ideal for businesses or developers seeking lightweight yet powerful AI solutions that can operate in diverse multilingual settings without the high computational demand of larger models.
Click here for the [original model card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md).
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| meta-llama/llama-3.2-90b-vision-instruct | 2024-09-25 | $1.20 | $1.20 | 131,072 | No | Yes | No | No | The Llama 90B Vision model is a top-tier, 90-billion-parameter multimodal model designed for the most challenging visual reasoning and language tasks. It offers unparalleled accuracy in image captioning, visual question answering, and advanced image-text comprehension. Pre-trained on vast multimodal datasets and fine-tuned with human feedback, the Llama 90B Vision is engineered to handle the most demanding image-based AI tasks.
This model is perfect for industries requiring cutting-edge multimodal AI capabilities, particularly those dealing with complex, real-time visual and textual analysis.
Click here for the [original model card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD_VISION.md).
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| meta-llama/llama-3.2-11b-vision-instruct:free | 2024-09-25 | $0.00 | $0.00 | 131,072 | No | No | No | No | Llama 3.2 11B Vision is a multimodal model with 11 billion parameters, designed to handle tasks combining visual and textual data. It excels in tasks such as image captioning and visual question answering, bridging the gap between language generation and visual reasoning. Pre-trained on a massive dataset of image-text pairs, it performs well in complex, high-accuracy image analysis.
Its ability to integrate visual understanding with language processing makes it an ideal solution for industries requiring comprehensive visual-linguistic AI applications, such as content creation, AI-driven customer service, and research.
Click here for the [original model card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD_VISION.md).
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| meta-llama/llama-3.2-11b-vision-instruct | 2024-09-25 | $0.05 | $0.05 | 131,072 | Yes | Yes | No | No | Llama 3.2 11B Vision is a multimodal model with 11 billion parameters, designed to handle tasks combining visual and textual data. It excels in tasks such as image captioning and visual question answering, bridging the gap between language generation and visual reasoning. Pre-trained on a massive dataset of image-text pairs, it performs well in complex, high-accuracy image analysis.
Its ability to integrate visual understanding with language processing makes it an ideal solution for industries requiring comprehensive visual-linguistic AI applications, such as content creation, AI-driven customer service, and research.
Click here for the [original model card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD_VISION.md).
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://www.llama.com/llama3/use-policy/). |
| qwen/qwen-2.5-72b-instruct:free | 2024-09-19 | $0.00 | $0.00 | 32,768 | No | No | No | No | Qwen2.5 72B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:
– Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.
– Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.
– Long-context Support up to 128K tokens and can generate up to 8K tokens.
– Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
Usage of this model is subject to [Tongyi Qianwen LICENSE AGREEMENT](https://huggingface.co/Qwen/Qwen1.5-110B-Chat/blob/main/LICENSE). |
| qwen/qwen-2.5-72b-instruct | 2024-09-19 | $0.07 | $0.27 | 32,768 | No | Yes | No | No | Qwen2.5 72B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:
– Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.
– Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.
– Long-context Support up to 128K tokens and can generate up to 8K tokens.
– Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
Usage of this model is subject to [Tongyi Qianwen LICENSE AGREEMENT](https://huggingface.co/Qwen/Qwen1.5-110B-Chat/blob/main/LICENSE). |
| neversleep/llama-3.1-lumimaid-8b | 2024-09-15 | $0.17 | $0.99 | 40,000 | Yes | Yes | No | No | Lumimaid v0.2 8B is a finetune of [Llama 3.1 8B](/models/meta-llama/llama-3.1-8b-instruct) with a “HUGE step up dataset wise” compared to Lumimaid v0.1. Sloppy chats output were purged.
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| openai/o1-mini | 2024-09-12 | $1.10 | $4.40 | 128,000 | No | No | No | No | The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding.
The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the [launch announcement](https://openai.com/o1).
Note: This model is currently experimental and not suitable for production use-cases, and may be heavily rate-limited. |
| openai/o1-mini-2024-09-12 | 2024-09-12 | $1.10 | $4.40 | 128,000 | No | No | No | No | The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding.
The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the [launch announcement](https://openai.com/o1).
Note: This model is currently experimental and not suitable for production use-cases, and may be heavily rate-limited. |
| mistralai/pixtral-12b | 2024-09-10 | $0.10 | $0.10 | 32,768 | Yes | Yes | No | No | The first multi-modal, text+image-to-text model from Mistral AI. Its weights were launched via torrent: https://x.com/mistralai/status/1833758285167722836. |
| cohere/command-r-plus-08-2024 | 2024-08-30 | $2.50 | $10.00 | 128,000 | Yes | Yes | No | No | command-r-plus-08-2024 is an update of the [Command R+](/models/cohere/command-r-plus) with roughly 50% higher throughput and 25% lower latencies as compared to the previous Command R+ version, while keeping the hardware footprint the same.
Read the launch post [here](https://docs.cohere.com/changelog/command-gets-refreshed).
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| cohere/command-r-08-2024 | 2024-08-30 | $0.15 | $0.60 | 128,000 | Yes | Yes | No | No | command-r-08-2024 is an update of the [Command R](/models/cohere/command-r) with improved performance for multilingual retrieval-augmented generation (RAG) and tool use. More broadly, it is better at math, code and reasoning and is competitive with the previous version of the larger Command R+ model.
Read the launch post [here](https://docs.cohere.com/changelog/command-gets-refreshed).
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| qwen/qwen-2.5-vl-7b-instruct | 2024-08-28 | $0.20 | $0.20 | 32,768 | Yes | Yes | No | No | Qwen2.5 VL 7B is a multimodal LLM from the Qwen Team with the following key enhancements:
– SoTA understanding of images of various resolution & ratio: Qwen2.5-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc.
– Understanding videos of 20min+: Qwen2.5-VL can understand videos over 20 minutes for high-quality video-based question answering, dialog, content creation, etc.
– Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2.5-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.
– Multilingual Support: to serve global users, besides English and Chinese, Qwen2.5-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc.
For more details, see this [blog post](https://qwenlm.github.io/blog/qwen2-vl/) and [GitHub repo](https://github.com/QwenLM/Qwen2-VL).
Usage of this model is subject to [Tongyi Qianwen LICENSE AGREEMENT](https://huggingface.co/Qwen/Qwen1.5-110B-Chat/blob/main/LICENSE). |
| sao10k/l3.1-euryale-70b | 2024-08-28 | $0.65 | $0.75 | 32,768 | Yes | Yes | No | No | Euryale L3.1 70B v2.2 is a model focused on creative roleplay from [Sao10k](https://ko-fi.com/sao10k). It is the successor of [Euryale L3 70B v2.1](/models/sao10k/l3-euryale-70b). |
| microsoft/phi-3.5-mini-128k-instruct | 2024-08-21 | $0.10 | $0.10 | 128,000 | No | No | No | No | Phi-3.5 models are lightweight, state-of-the-art open models. These models were trained with Phi-3 datasets that include both synthetic data and the filtered, publicly available websites data, with a focus on high quality and reasoning-dense properties. Phi-3.5 Mini uses 3.8B parameters, and is a dense decoder-only transformer model using the same tokenizer as [Phi-3 Mini](/models/microsoft/phi-3-mini-128k-instruct).
The models underwent a rigorous enhancement process, incorporating both supervised fine-tuning, proximal policy optimization, and direct preference optimization to ensure precise instruction adherence and robust safety measures. When assessed against benchmarks that test common sense, language understanding, math, code, long context and logical reasoning, Phi-3.5 models showcased robust and state-of-the-art performance among models with less than 13 billion parameters. |
| nousresearch/hermes-3-llama-3.1-70b | 2024-08-18 | $0.10 | $0.28 | 131,072 | Yes | Yes | No | No | Hermes 3 is a generalist language model with many improvements over [Hermes 2](/models/nousresearch/nous-hermes-2-mistral-7b-dpo), including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board.
Hermes 3 70B is a competitive, if not superior finetune of the [Llama-3.1 70B foundation model](/models/meta-llama/llama-3.1-70b-instruct), focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user.
The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including more powerful and reliable function calling and structured output capabilities, generalist assistant capabilities, and improved code generation skills. |
| nousresearch/hermes-3-llama-3.1-405b | 2024-08-16 | $0.70 | $0.80 | 131,072 | No | Yes | No | No | Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board.
Hermes 3 405B is a frontier-level, full-parameter finetune of the Llama-3.1 405B foundation model, focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user.
The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including more powerful and reliable function calling and structured output capabilities, generalist assistant capabilities, and improved code generation skills.
Hermes 3 is competitive, if not superior, to Llama-3.1 Instruct models at general capabilities, with varying strengths and weaknesses attributable between the two. |
| openai/chatgpt-4o-latest | 2024-08-14 | $5.00 | $15.00 | 128,000 | Yes | Yes | No | No | OpenAI ChatGPT 4o is continually updated by OpenAI to point to the current version of GPT-4o used by ChatGPT. It therefore differs slightly from the API version of [GPT-4o](/models/openai/gpt-4o) in that it has additional RLHF. It is intended for research and evaluation.
OpenAI notes that this model is not suited for production use-cases as it may be removed or redirected to another model in the future. |
| sao10k/l3-lunaris-8b | 2024-08-13 | $0.02 | $0.05 | 8,192 | No | Yes | No | No | Lunaris 8B is a versatile generalist and roleplaying model based on Llama 3. It’s a strategic merge of multiple models, designed to balance creativity with improved logic and general knowledge.
Created by [Sao10k](https://huggingface.co/Sao10k), this model aims to offer an improved experience over Stheno v3.2, with enhanced creativity and logical reasoning.
For best results, use with Llama 3 Instruct context template, temperature 1.4, and min_p 0.1. |
| openai/gpt-4o-2024-08-06 | 2024-08-06 | $2.50 | $10.00 | 128,000 | Yes | Yes | No | No | The 2024-08-06 version of GPT-4o offers improved performance in structured outputs, with the ability to supply a JSON schema in the respone_format. Read more [here](https://openai.com/index/introducing-structured-outputs-in-the-api/).
GPT-4o (“o” for “omni”) is OpenAI’s latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/openai/gpt-4-turbo) while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities.
For benchmarking against other models, it was briefly called [“im-also-a-good-gpt2-chatbot”](https://twitter.com/LiamFedus/status/1790064963966370209) |
| meta-llama/llama-3.1-405b | 2024-08-02 | $2.00 | $2.00 | 32,768 | No | No | No | No | Meta’s latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This is the base 405B pre-trained version.
It has demonstrated strong performance compared to leading closed-source models in human evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| meta-llama/llama-3.1-8b-instruct | 2024-07-23 | $0.01 | $0.02 | 131,072 | Yes | Yes | No | No | Meta’s latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 8B instruct-tuned version is fast and efficient.
It has demonstrated strong performance compared to leading closed-source models in human evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3-1/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| meta-llama/llama-3.1-405b-instruct:free | 2024-07-23 | $0.00 | $0.00 | 65,536 | Yes | Yes | No | No | The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs.
Meta’s latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 405B instruct-tuned version is optimized for high quality dialogue usecases.
It has demonstrated strong performance compared to leading closed-source models including GPT-4o and Claude 3.5 Sonnet in evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3-1/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| meta-llama/llama-3.1-405b-instruct | 2024-07-23 | $0.80 | $0.80 | 32,768 | Yes | Yes | No | No | The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs.
Meta’s latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 405B instruct-tuned version is optimized for high quality dialogue usecases.
It has demonstrated strong performance compared to leading closed-source models including GPT-4o and Claude 3.5 Sonnet in evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3-1/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| meta-llama/llama-3.1-70b-instruct | 2024-07-23 | $0.10 | $0.28 | 131,072 | Yes | Yes | No | No | Meta’s latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 70B instruct-tuned version is optimized for high quality dialogue usecases.
It has demonstrated strong performance compared to leading closed-source models in human evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3-1/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| mistralai/mistral-nemo:free | 2024-07-19 | $0.00 | $0.00 | 131,072 | No | No | No | No | A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA.
The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
It supports function calling and is released under the Apache 2.0 license. |
| mistralai/mistral-nemo | 2024-07-19 | $0.01 | $0.05 | 32,000 | Yes | Yes | No | No | A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA.
The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
It supports function calling and is released under the Apache 2.0 license. |
| openai/gpt-4o-mini | 2024-07-18 | $0.15 | $0.60 | 128,000 | Yes | Yes | No | No | GPT-4o mini is OpenAI’s newest model after [GPT-4 Omni](/models/openai/gpt-4o), supporting both text and image inputs with text outputs.
As their most advanced small model, it is many multiples more affordable than other recent frontier models, and more than 60% cheaper than [GPT-3.5 Turbo](/models/openai/gpt-3.5-turbo). It maintains SOTA intelligence, while being significantly more cost-effective.
GPT-4o mini achieves an 82% score on MMLU and presently ranks higher than GPT-4 on chat preferences [common leaderboards](https://arena.lmsys.org/).
Check out the [launch announcement](https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/) to learn more.
#multimodal |
| openai/gpt-4o-mini-2024-07-18 | 2024-07-18 | $0.15 | $0.60 | 128,000 | Yes | Yes | No | No | GPT-4o mini is OpenAI’s newest model after [GPT-4 Omni](/models/openai/gpt-4o), supporting both text and image inputs with text outputs.
As their most advanced small model, it is many multiples more affordable than other recent frontier models, and more than 60% cheaper than [GPT-3.5 Turbo](/models/openai/gpt-3.5-turbo). It maintains SOTA intelligence, while being significantly more cost-effective.
GPT-4o mini achieves an 82% score on MMLU and presently ranks higher than GPT-4 on chat preferences [common leaderboards](https://arena.lmsys.org/).
Check out the [launch announcement](https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/) to learn more.
#multimodal |
| google/gemma-2-27b-it | 2024-07-13 | $0.65 | $0.65 | 8,192 | Yes | Yes | No | No | Gemma 2 27B by Google is an open model built from the same research and technology used to create the [Gemini models](/models?q=gemini).
Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning.
See the [launch announcement](https://blog.google/technology/developers/google-gemma-2/) for more details. Usage of Gemma is subject to Google’s [Gemma Terms of Use](https://ai.google.dev/gemma/terms). |
| google/gemma-2-9b-it:free | 2024-06-28 | $0.00 | $0.00 | 8,192 | No | No | No | No | Gemma 2 9B by Google is an advanced, open-source language model that sets a new standard for efficiency and performance in its size class.
Designed for a wide variety of tasks, it empowers developers and researchers to build innovative applications, while maintaining accessibility, safety, and cost-effectiveness.
See the [launch announcement](https://blog.google/technology/developers/google-gemma-2/) for more details. Usage of Gemma is subject to Google’s [Gemma Terms of Use](https://ai.google.dev/gemma/terms). |
| google/gemma-2-9b-it | 2024-06-28 | $0.01 | $0.01 | 8,192 | No | Yes | No | No | Gemma 2 9B by Google is an advanced, open-source language model that sets a new standard for efficiency and performance in its size class.
Designed for a wide variety of tasks, it empowers developers and researchers to build innovative applications, while maintaining accessibility, safety, and cost-effectiveness.
See the [launch announcement](https://blog.google/technology/developers/google-gemma-2/) for more details. Usage of Gemma is subject to Google’s [Gemma Terms of Use](https://ai.google.dev/gemma/terms). |
| anthropic/claude-3.5-sonnet-20240620 | 2024-06-20 | $3.00 | $15.00 | 200,000 | No | No | No | No | Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:
– Coding: Autonomously writes, edits, and runs code with reasoning and troubleshooting
– Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights
– Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone
– Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems)
For the latest version (2024-10-23), check out [Claude 3.5 Sonnet](/anthropic/claude-3.5-sonnet).
#multimodal |
| sao10k/l3-euryale-70b | 2024-06-18 | $1.48 | $1.48 | 8,192 | No | No | No | No | Euryale 70B v2.1 is a model focused on creative roleplay from [Sao10k](https://ko-fi.com/sao10k).
– Better prompt adherence.
– Better anatomy / spatial awareness.
– Adapts much better to unique and custom formatting / reply formats.
– Very creative, lots of unique swipes.
– Is not restrictive during roleplays. |
| cognitivecomputations/dolphin-mixtral-8x22b | 2024-06-08 | $0.90 | $0.90 | 16,000 | No | No | No | No | Dolphin 2.9 is designed for instruction following, conversational, and coding. This model is a finetune of [Mixtral 8x22B Instruct](/models/mistralai/mixtral-8x22b-instruct). It features a 64k context length and was fine-tuned with a 16k sequence length using ChatML templates.
This model is a successor to [Dolphin Mixtral 8x7B](/models/cognitivecomputations/dolphin-mixtral-8x7b).
The model is uncensored and is stripped of alignment and bias. It requires an external alignment layer for ethical use. Users are cautioned to use this highly compliant model responsibly, as detailed in a blog post about uncensored models at [erichartford.com/uncensored-models](https://erichartford.com/uncensored-models).
#moe #uncensored |
| qwen/qwen-2-72b-instruct | 2024-06-07 | $0.90 | $0.90 | 32,768 | No | No | No | No | Qwen2 72B is a transformer-based model that excels in language understanding, multilingual capabilities, coding, mathematics, and reasoning.
It features SwiGLU activation, attention QKV bias, and group query attention. It is pretrained on extensive data with supervised finetuning and direct preference optimization.
For more details, see this [blog post](https://qwenlm.github.io/blog/qwen2/) and [GitHub repo](https://github.com/QwenLM/Qwen2).
Usage of this model is subject to [Tongyi Qianwen LICENSE AGREEMENT](https://huggingface.co/Qwen/Qwen1.5-110B-Chat/blob/main/LICENSE). |
| mistralai/mistral-7b-instruct:free | 2024-05-27 | $0.00 | $0.00 | 32,768 | No | Yes | No | No | A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.
*Mistral 7B Instruct has multiple version variants, and this is intended to be the latest version.* |
| mistralai/mistral-7b-instruct | 2024-05-27 | $0.03 | $0.05 | 32,768 | No | Yes | No | No | A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.
*Mistral 7B Instruct has multiple version variants, and this is intended to be the latest version.* |
| nousresearch/hermes-2-pro-llama-3-8b | 2024-05-27 | $0.02 | $0.04 | 131,072 | Yes | Yes | No | No | Hermes 2 Pro is an upgraded, retrained version of Nous Hermes 2, consisting of an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house. |
| mistralai/mistral-7b-instruct-v0.3 | 2024-05-27 | $0.03 | $0.05 | 32,768 | No | Yes | No | No | A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.
An improved version of [Mistral 7B Instruct v0.2](/models/mistralai/mistral-7b-instruct-v0.2), with the following changes:
– Extended vocabulary to 32768
– Supports v3 Tokenizer
– Supports function calling
NOTE: Support for function calling depends on the provider. |
| microsoft/phi-3-mini-128k-instruct | 2024-05-26 | $0.10 | $0.10 | 128,000 | No | No | No | No | Phi-3 Mini is a powerful 3.8B parameter model designed for advanced language understanding, reasoning, and instruction following. Optimized through supervised fine-tuning and preference adjustments, it excels in tasks involving common sense, mathematics, logical reasoning, and code processing.
At time of release, Phi-3 Medium demonstrated state-of-the-art performance among lightweight models. This model is static, trained on an offline dataset with an October 2023 cutoff date. |
| microsoft/phi-3-medium-128k-instruct | 2024-05-24 | $1.00 | $1.00 | 128,000 | No | No | No | No | Phi-3 128K Medium is a powerful 14-billion parameter model designed for advanced language understanding, reasoning, and instruction following. Optimized through supervised fine-tuning and preference adjustments, it excels in tasks involving common sense, mathematics, logical reasoning, and code processing.
At time of release, Phi-3 Medium demonstrated state-of-the-art performance among lightweight models. In the MMLU-Pro eval, the model even comes close to a Llama3 70B level of performance.
For 4k context length, try [Phi-3 Medium 4K](/models/microsoft/phi-3-medium-4k-instruct). |
| neversleep/llama-3-lumimaid-70b | 2024-05-16 | $4.00 | $6.00 | 8,192 | No | No | No | No | The NeverSleep team is back, with a Llama 3 70B finetune trained on their curated roleplay data. Striking a balance between eRP and RP, Lumimaid was designed to be serious, yet uncensored when necessary.
To enhance it’s overall intelligence and chat capability, roughly 40% of the training data was not roleplay. This provides a breadth of knowledge to access, while still keeping roleplay as the primary strength.
Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| google/gemini-flash-1.5 | 2024-05-14 | $0.07 | $0.30 | 1,000,000 | Yes | Yes | No | No | Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video. It’s adept at processing visual and text inputs such as photographs, documents, infographics, and screenshots.
Gemini 1.5 Flash is designed for high-volume, high-frequency tasks where cost and latency matter. On most common tasks, Flash achieves comparable quality to other Gemini Pro models at a significantly reduced cost. Flash is well-suited for applications like chat assistants and on-demand content generation where speed and scale matter.
Usage of Gemini is subject to Google’s [Gemini Terms of Use](https://ai.google.dev/terms).
#multimodal |
| openai/gpt-4o | 2024-05-13 | $2.50 | $10.00 | 128,000 | Yes | Yes | No | No | GPT-4o (“o” for “omni”) is OpenAI’s latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/openai/gpt-4-turbo) while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities.
For benchmarking against other models, it was briefly called [“im-also-a-good-gpt2-chatbot”](https://twitter.com/LiamFedus/status/1790064963966370209)
#multimodal |
| openai/gpt-4o:extended | 2024-05-13 | $6.00 | $18.00 | 128,000 | Yes | Yes | No | No | GPT-4o (“o” for “omni”) is OpenAI’s latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/openai/gpt-4-turbo) while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities.
For benchmarking against other models, it was briefly called [“im-also-a-good-gpt2-chatbot”](https://twitter.com/LiamFedus/status/1790064963966370209)
#multimodal |
| meta-llama/llama-guard-2-8b | 2024-05-13 | $0.20 | $0.20 | 8,192 | No | No | No | No | This safeguard model has 8B parameters and is based on the Llama 3 family. Just like is predecessor, [LlamaGuard 1](https://huggingface.co/meta-llama/LlamaGuard-7b), it can do both prompt and response classification.
LlamaGuard 2 acts as a normal LLM would, generating text that indicates whether the given input/output is safe/unsafe. If deemed unsafe, it will also share the content categories violated.
For best results, please use raw prompt input or the `/completions` endpoint, instead of the chat API.
It has demonstrated strong performance compared to leading closed-source models in human evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| openai/gpt-4o-2024-05-13 | 2024-05-13 | $5.00 | $15.00 | 128,000 | Yes | Yes | No | No | GPT-4o (“o” for “omni”) is OpenAI’s latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of [GPT-4 Turbo](/models/openai/gpt-4-turbo) while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities.
For benchmarking against other models, it was briefly called [“im-also-a-good-gpt2-chatbot”](https://twitter.com/LiamFedus/status/1790064963966370209)
#multimodal |
| meta-llama/llama-3-8b-instruct | 2024-04-18 | $0.03 | $0.06 | 8,192 | No | Yes | No | No | Meta’s latest class of model (Llama 3) launched with a variety of sizes & flavors. This 8B instruct-tuned version was optimized for high quality dialogue usecases.
It has demonstrated strong performance compared to leading closed-source models in human evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| meta-llama/llama-3-70b-instruct | 2024-04-18 | $0.30 | $0.40 | 8,192 | No | Yes | No | No | Meta’s latest class of model (Llama 3) launched with a variety of sizes & flavors. This 70B instruct-tuned version was optimized for high quality dialogue usecases.
It has demonstrated strong performance compared to leading closed-source models in human evaluations.
To read more about the model release, [click here](https://ai.meta.com/blog/meta-llama-3/). Usage of this model is subject to [Meta’s Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/). |
| mistralai/mixtral-8x22b-instruct | 2024-04-17 | $0.90 | $0.90 | 65,536 | Yes | Yes | No | No | Mistral’s official instruct fine-tuned version of [Mixtral 8x22B](/models/mistralai/mixtral-8x22b). It uses 39B active parameters out of 141B, offering unparalleled cost efficiency for its size. Its strengths include:
– strong math, coding, and reasoning
– large context length (64k)
– fluency in English, French, Italian, German, and Spanish
See benchmarks on the launch announcement [here](https://mistral.ai/news/mixtral-8x22b/).
#moe |
| microsoft/wizardlm-2-8x22b | 2024-04-16 | $0.48 | $0.48 | 65,536 | No | Yes | No | No | WizardLM-2 8x22B is Microsoft AI’s most advanced Wizard model. It demonstrates highly competitive performance compared to leading proprietary models, and it consistently outperforms all existing state-of-the-art opensource models.
It is an instruct finetune of [Mixtral 8x22B](/models/mistralai/mixtral-8x22b).
To read more about the model release, [click here](https://wizardlm.github.io/WizardLM2/).
#moe |
| google/gemini-pro-1.5 | 2024-04-09 | $1.25 | $5.00 | 2,000,000 | Yes | Yes | No | No | Google’s latest multimodal model, supports image and video[0] in text or chat prompts.
Optimized for language tasks including:
– Code generation
– Text generation
– Text editing
– Problem solving
– Recommendations
– Information extraction
– Data extraction or generation
– AI agents
Usage of Gemini is subject to Google’s [Gemini Terms of Use](https://ai.google.dev/terms).
* [0]: Video input is not available through OpenRouter at this time. |
| openai/gpt-4-turbo | 2024-04-09 | $10.00 | $30.00 | 128,000 | Yes | Yes | No | No | The latest GPT-4 Turbo model with vision capabilities. Vision requests can now use JSON mode and function calling.
Training data: up to December 2023. |
| cohere/command-r-plus | 2024-04-04 | $3.00 | $15.00 | 128,000 | Yes | Yes | No | No | Command R+ is a new, 104B-parameter LLM from Cohere. It’s useful for roleplay, general consumer usecases, and Retrieval Augmented Generation (RAG).
It offers multilingual support for ten key languages to facilitate global business operations. See benchmarks and the launch post [here](https://txt.cohere.com/command-r-plus-microsoft-azure/).
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| cohere/command-r-plus-04-2024 | 2024-04-02 | $3.00 | $15.00 | 128,000 | Yes | Yes | No | No | Command R+ is a new, 104B-parameter LLM from Cohere. It’s useful for roleplay, general consumer usecases, and Retrieval Augmented Generation (RAG).
It offers multilingual support for ten key languages to facilitate global business operations. See benchmarks and the launch post [here](https://txt.cohere.com/command-r-plus-microsoft-azure/).
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| sophosympatheia/midnight-rose-70b | 2024-03-22 | $0.80 | $0.80 | 4,096 | No | No | No | No | A merge with a complex family tree, this model was crafted for roleplaying and storytelling. Midnight Rose is a successor to Rogue Rose and Aurora Nights and improves upon them both. It wants to produce lengthy output by default and is the best creative writing merge produced so far by sophosympatheia.
Descending from earlier versions of Midnight Rose and [Wizard Tulu Dolphin 70B](https://huggingface.co/sophosympatheia/Wizard-Tulu-Dolphin-70B-v1.0), it inherits the best qualities of each. |
| cohere/command | 2024-03-14 | $1.00 | $2.00 | 4,096 | Yes | Yes | No | No | Command is an instruction-following conversational model that performs language tasks with high quality, more reliably and with a longer context than our base generative models.
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| cohere/command-r | 2024-03-14 | $0.50 | $1.50 | 128,000 | Yes | Yes | No | No | Command-R is a 35B parameter model that performs conversational language tasks at a higher quality, more reliably, and with a longer context than previous models. It can be used for complex workflows like code generation, retrieval augmented generation (RAG), tool use, and agents.
Read the launch post [here](https://txt.cohere.com/command-r/).
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| anthropic/claude-3-haiku | 2024-03-13 | $0.25 | $1.25 | 200,000 | No | No | No | No | Claude 3 Haiku is Anthropic’s fastest and most compact model for
near-instant responsiveness. Quick and accurate targeted performance.
See the launch announcement and benchmark results [here](https://www.anthropic.com/news/claude-3-haiku)
#multimodal |
| anthropic/claude-3-opus | 2024-03-05 | $15.00 | $75.00 | 200,000 | No | No | No | No | Claude 3 Opus is Anthropic’s most powerful model for highly complex tasks. It boasts top-level performance, intelligence, fluency, and understanding.
See the launch announcement and benchmark results [here](https://www.anthropic.com/news/claude-3-family)
#multimodal |
| cohere/command-r-03-2024 | 2024-03-02 | $0.50 | $1.50 | 128,000 | Yes | Yes | No | No | Command-R is a 35B parameter model that performs conversational language tasks at a higher quality, more reliably, and with a longer context than previous models. It can be used for complex workflows like code generation, retrieval augmented generation (RAG), tool use, and agents.
Read the launch post [here](https://txt.cohere.com/command-r/).
Use of this model is subject to Cohere’s [Usage Policy](https://docs.cohere.com/docs/usage-policy) and [SaaS Agreement](https://cohere.com/saas-agreement). |
| mistralai/mistral-large | 2024-02-26 | $2.00 | $6.00 | 128,000 | Yes | Yes | No | No | This is Mistral AI’s flagship model, Mistral Large 2 (version `mistral-large-2407`). It’s a proprietary weights-available model and excels at reasoning, code, JSON, chat, and more. Read the launch announcement [here](https://mistral.ai/news/mistral-large-2407/).
It supports dozens of languages including French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80+ coding languages including Python, Java, C, C++, JavaScript, and Bash. Its long context window allows precise information recall from large documents. |
| openai/gpt-3.5-turbo-0613 | 2024-01-25 | $1.00 | $2.00 | 4,095 | Yes | Yes | No | No | GPT-3.5 Turbo is OpenAI’s fastest model. It can understand and generate natural language or code, and is optimized for chat and traditional completion tasks.
Training data up to Sep 2021. |
| openai/gpt-4-turbo-preview | 2024-01-25 | $10.00 | $30.00 | 128,000 | Yes | Yes | No | No | The preview GPT-4 model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Training data: up to Dec 2023.
**Note:** heavily rate limited by OpenAI while in preview. |
| nousresearch/nous-hermes-2-mixtral-8x7b-dpo | 2024-01-16 | $0.60 | $0.60 | 32,768 | No | No | No | No | Nous Hermes 2 Mixtral 8x7B DPO is the new flagship Nous Research model trained over the [Mixtral 8x7B MoE LLM](/models/mistralai/mixtral-8x7b).
The model was trained on over 1,000,000 entries of primarily [GPT-4](/models/openai/gpt-4) generated data, as well as other high quality data from open datasets across the AI landscape, achieving state of the art performance on a variety of tasks.
#moe |
| mistralai/mistral-small | 2024-01-10 | $0.20 | $0.60 | 32,768 | Yes | Yes | No | No | With 22 billion parameters, Mistral Small v24.09 offers a convenient mid-point between (Mistral NeMo 12B)[/mistralai/mistral-nemo] and (Mistral Large 2)[/mistralai/mistral-large], providing a cost-effective solution that can be deployed across various platforms and environments. It has better reasoning, exhibits more capabilities, can produce and reason about code, and is multiligual, supporting English, French, German, Italian, and Spanish. |
| mistralai/mistral-tiny | 2024-01-10 | $0.25 | $0.25 | 32,768 | Yes | Yes | No | No | Note: This model is being deprecated. Recommended replacement is the newer [Ministral 8B](/mistral/ministral-8b)
This model is currently powered by Mistral-7B-v0.2, and incorporates a “better” fine-tuning than [Mistral 7B](/models/mistralai/mistral-7b-instruct-v0.1), inspired by community work. It’s best used for large batch processing tasks where cost is a significant factor but reasoning capabilities are not crucial. |
| mistralai/mistral-7b-instruct-v0.2 | 2023-12-28 | $0.20 | $0.20 | 32,768 | No | No | No | No | A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.
An improved version of [Mistral 7B Instruct](/modelsmistralai/mistral-7b-instruct-v0.1), with the following changes:
– 32k context window (vs 8k context in v0.1)
– Rope-theta = 1e6
– No Sliding-Window Attention |
| mistralai/mixtral-8x7b-instruct | 2023-12-10 | $0.08 | $0.24 | 32,768 | No | Yes | No | No | Mixtral 8x7B Instruct is a pretrained generative Sparse Mixture of Experts, by Mistral AI, for chat and instruction use. Incorporates 8 experts (feed-forward networks) for a total of 47 billion parameters.
Instruct model fine-tuned by Mistral. #moe |
| neversleep/noromaid-20b | 2023-11-26 | $1.00 | $1.75 | 4,096 | Yes | Yes | No | No | A collab between IkariDev and Undi. This merge is suitable for RP, ERP, and general knowledge.
#merge #uncensored |
| alpindale/goliath-120b | 2023-11-10 | $9.00 | $11.00 | 6,144 | Yes | Yes | No | No | A large LLM created by combining two fine-tuned Llama 70B models into one 120B model. Combines Xwin and Euryale.
Credits to
– [@chargoddard](https://huggingface.co/chargoddard) for developing the framework used to merge the model – [mergekit](https://github.com/cg123/mergekit).
– [@Undi95](https://huggingface.co/Undi95) for helping with the merge ratios.
#merge |
| openai/gpt-4-1106-preview | 2023-11-06 | $10.00 | $30.00 | 128,000 | Yes | Yes | No | No | The latest GPT-4 Turbo model with vision capabilities. Vision requests can now use JSON mode and function calling.
Training data: up to April 2023. |
| openai/gpt-3.5-turbo-instruct | 2023-09-28 | $1.50 | $2.00 | 4,095 | Yes | Yes | No | No | This model is a variant of GPT-3.5 Turbo tuned for instructional prompts and omitting chat-related optimizations. Training data: up to Sep 2021. |
| mistralai/mistral-7b-instruct-v0.1 | 2023-09-28 | $0.11 | $0.19 | 2,824 | No | No | No | No | A 7.3B parameter model that outperforms Llama 2 13B on all benchmarks, with optimizations for speed and context length. |
| pygmalionai/mythalion-13b | 2023-09-02 | $0.70 | $1.10 | 4,096 | No | No | No | No | A blend of the new Pygmalion-13b and MythoMax. #merge |
| openai/gpt-3.5-turbo-16k | 2023-08-28 | $3.00 | $4.00 | 16,385 | Yes | Yes | No | No | This model offers four times the context length of gpt-3.5-turbo, allowing it to support approximately 20 pages of text in a single request at a higher cost. Training data: up to Sep 2021. |
| mancer/weaver | 2023-08-02 | $1.50 | $1.50 | 8,000 | No | No | No | No | An attempt to recreate Claude-style verbosity, but don’t expect the same level of coherence or memory. Meant for use in roleplay/narrative situations. |
| undi95/remm-slerp-l2-13b | 2023-07-22 | $0.70 | $1.00 | 6,144 | Yes | Yes | No | No | A recreation trial of the original MythoMax-L2-B13 but with updated models. #merge |
| gryphe/mythomax-l2-13b | 2023-07-02 | $0.06 | $0.06 | 4,096 | Yes | Yes | No | No | One of the highest performing and most popular fine-tunes of Llama 2 13B, with rich descriptions and roleplay. #merge |
| openai/gpt-3.5-turbo | 2023-05-28 | $0.50 | $1.50 | 16,385 | Yes | Yes | No | No | GPT-3.5 Turbo is OpenAI’s fastest model. It can understand and generate natural language or code, and is optimized for chat and traditional completion tasks.
Training data up to Sep 2021. |
| openai/gpt-4 | 2023-05-28 | $30.00 | $60.00 | 8,191 | Yes | Yes | No | No | OpenAI’s flagship model, GPT-4 is a large-scale multimodal language model capable of solving difficult problems with greater accuracy than previous models due to its broader general knowledge and advanced reasoning capabilities. Training data: up to Sep 2021. |
| openai/gpt-4-0314 | 2023-05-28 | $30.00 | $60.00 | 8,191 | Yes | Yes | No | No | GPT-4-0314 is the first version of GPT-4 released, with a context length of 8,192 tokens, and was supported until June 14. Training data: up to Sep 2021. |
Notes
1 To filter for LLMs which support structured outputs, click on Add Condition in the Custom Search Builder. Then select Structured Outputs Equals Yes.
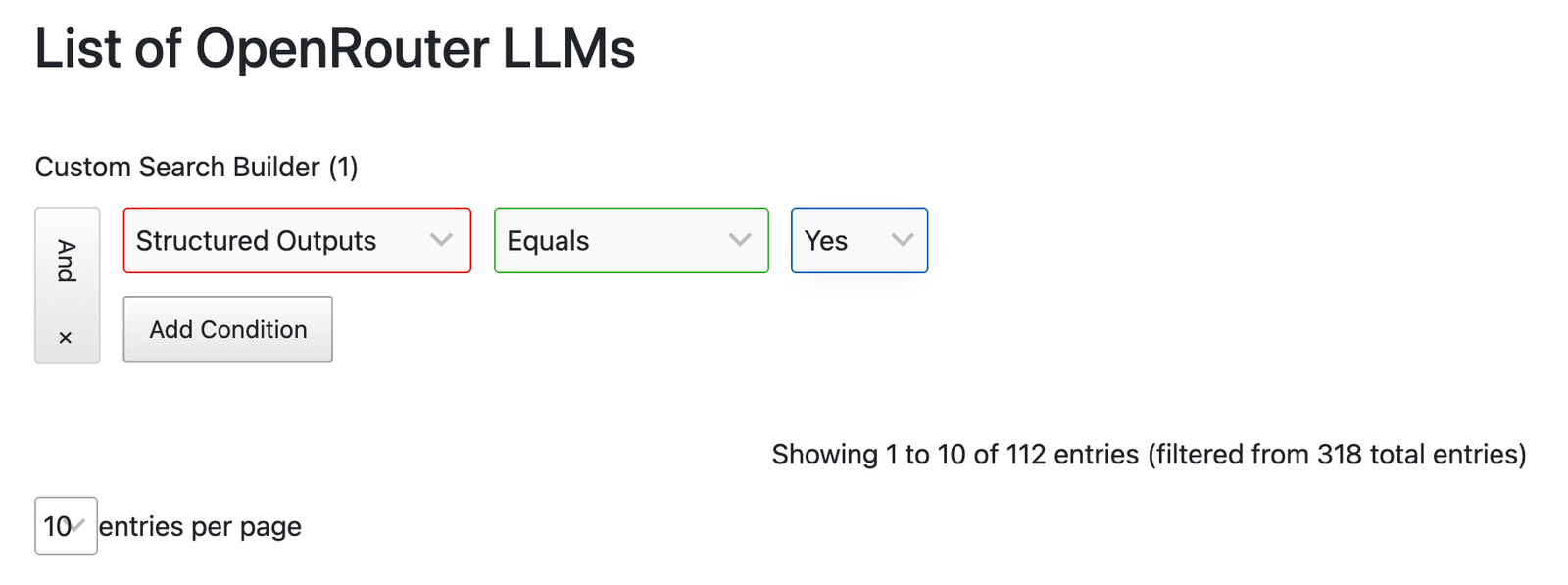
2 OpenRouter does not list all the models from its Models page in its API method which provides the list of models (and I am not sure why), but I did a spot check and saw that the most recently added models are all available in this API call.
3 You can click on the Description to see the full text, and click on it again to collapse (like a toggle)